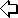

|
|
<- SL: Intro - Archivio Generale - Copertina - SL: GNU/Linux e autoloader -> |
|
Sistemi Liberi
L'articolo...Che il nostro sistema sia un server internet o una workstation per uso privato, è estremamente importante fare tutto quanto in nostro potere per garantirne la sicurezza. I motivi sono i più svariati: da semplici considerazioni riguardo l'importanza dei nostri dati, a vere e proprie questioni legali! La network security è un argomento affascinante, ma estremamente vasto e complesso; questo articolo vuole essere una introduzione teorica a ciò che, mooolto erroneamente, è creduto la panacea di tutti i mali: il firewall. |
Vorrei partire da una considerazione ovvia (tanto
ovvia,
che spesso viene assolutamente dimenticata): nessun firewall o IDS
potrà
mai proteggere un sistema mal configurato (o in generale una applicazione
"bacata").
Da questo, emerge l'importanza di concepire il termine "security"
come un'attitudine programmatica e progettuale, e non un mero insieme di
accorgimenti
tecnici. A questo riguardo, non si può fare a meno di sottolineare
che
ogni intervento mirato ad aumentare il livello di sicurezza implica
inevitabilmente
un aumento di costi, siano essi diretti (come l'acquisto di nuovo hardware)
o indiretti (ad esempio, aumento di complessità di alcune
operazioni).
La prima cosa che dovremmo puntualizzare è:
che
cosa si intende precisamente con il termine "firewall"? Se la domanda in
sè
è molto chiara, la risposta non può esserlo altrettanto. In
genere,
la difesa perimetrale si compone di un packet filter e di un
application
proxy; alcuni indicano con firewall l'insieme dei due, altri solamente
il
packet filter in senso stretto. Personalmente, propendo per la seconda
definizione
(vedremo in seguito come un packet filter e un application proxy lavorino a
livelli ISO/OSI assolutamente differenti).
Per quanto possa sembrare il solito argomento trito
e ritrito, il mio consiglio è quello di non saltare "a
piè
pari" questo paragrafo: la maggior parte delle richieste di aiuto che
troviamo
sulle mailing list derivano fondamentalmente proprio da una mancanza di
conoscenze
di base. Di seguito vorrei ricapitolare solamente ciò che ritengo
fondamentale
per capire bene cosa significhi pacchetto, firewall, circuito, ecc. Ed
è
per lo stesso motivo che la successiva analisi sarà fondamentalmente
orientata al protocollo TCP/IP (anche se, come vedremo in seguito, sarebbe
più
opportuno definirlo una "suite" di protocolli).
Il modello ISO/OSI (vedi fig.1)
descrive le modalità di interazione tra le componenti di rete
hardware
e software. I livelli più bassi definiscono il supporto fisico della
rete (cavo, scheda di rete o NIC, ecc); man mano che si sale, ciascun
livello
prepara i dati per il livello immediatamente superiore.

|
|
|
Il livello fisico (layer 1) è il
più
basso del modello OSI. Esso trasmette lo stream di bit su un supporto fisico
(ad esempio il cavo): rappresenta proprio il collegamento tra le interfacce
(elettriche ottiche, meccaniche...) e il cavo. Il livello data link
(layer
2) si occupa di "impacchettare" i bit ricevuti dal livello fisico
per trasformarli in un frame di dati, aggiungendo tra l'altro l'ID del
mittente,
del destinatario e il campo CRC. Il livello network (layer 3 )
è
responsabile dell'indirizzamento dei pacchetti, e della traduzione degli
indirizzi
da nomi logici a indirizzi fisici. Determina inoltre il percorso del
pacchetto
(routing) in base alle condizioni della rete, alla priorità di
servizio,
ecc. E' il layer che si occupa della frammentazione e successivo
riassemblaggio
di pacchetti troppo grandi. Il livello di trasporto (layer 4)
fornisce
il controllo di flusso, la gestione degli errori, le conferme di avvenuta
ricezione,
ecc. Il livello di sessione (layer 5) consente a due applicazioni su
differenti computer di comunicare utilizzando una connessione (detta appunto
sessione). Il livello di presentazione determina il formato per lo
scambio
dei dati tra i vari computer: esso riceve le informazioni dal livello
superiore,
trasformandole in un formato intermedio facilmente riconoscibile. Esso
è
il responsabile della conversione del protocollo, della codifica dei dati,
di
una eventuale conversione del set di caratteri, ecc. Si occupa inoltre della
compressione dati, per ridurre il numero di bit che verranno trasmessi. Il
livello
applicazione gestisce l'accesso ai servizi di rete da parte delle
varie
applicazioni, controllano l'accesso generale alla rete, il controllo del
flusso
e un eventuale recupero in caso di errori.
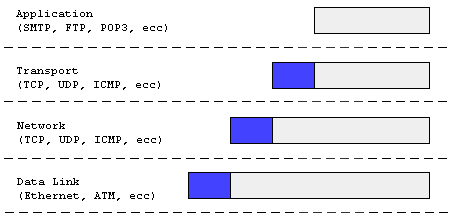
Alla luce di quanto detto finora, vediamo di capire
un po' meglio la struttura del pacchetto: a livello applicazione, esso
è
formato semplicemente dai dati da trasferire. Ma appena il pacchetto scende
al di sotto del layer 7, la sua struttura viene modificata, e ad esso viene
aggiunto un header (contenente informazioni relative al layer
stesso).
Il body invece contiene i dati, più l'header del livello
precedente;
questo processo prende il nome di encapsulation (vedi fig.2).
|
 |
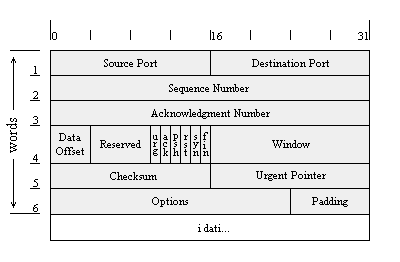
Il protocollo TCP si basa su un preciso schema di comunicazione, che deve garantire, oltre al normale trasferimento di dati, affidabilità (i pacchetti potrebbero venire danneggiati o persi, oppure duplicati), controllo del flusso e molteplicità di connessioni simultanee. Per quanto riguarda l'affidabilità e l'ordinamento dei byte, il protocollo TCP prevede l'utilizzo dei numeri di sequenza (sequence number) e dei flag (vedi fig. 4)
|
|
|
Ogni volta che una applicazione deve trasportare dati, trasmette una richiesta di connessione TCP al livello di trasporto del proprio computer il quale, a sua volta, invia a una porta del computer remoto un messaggio TCP con il flag di sincronizzazione settato. In gergo, questo si chiama un SYN packet (pacchetto con il flag di SYN a 1). Insieme al flag di SYN, il pacchetto contiene un numero casuale, detto numero di sequenza iniziale; ogni pacchetto successivamente inviato dal client verrà numerato partendo da questo numero. Il server, quando riceve il pacchetto SYN, risponde con un altro pacchetto SYN, ed un proprio numero di sequenza iniziale. Il pacchetto di risposta inviato dal server avrà un altro flag a 1, quello di ACK ( acknowledgement), contenente il numero inviato dal client incrementato di uno. In soldoni, il server sta dicendo al client che accetta ulteriori pacchetti, e che il prossimo pacchetto deve contenere il numero di sequenza indicato dall'ACK. A questo punto sarà il client a dare l'ACK al server, e fatto questo può iniziare la vera e propria comunicazione. Per quanto detto finora, si dice che l'hand shaking del protocollo TCP è costituito da tre passi. Per chiarimenti, vedere figura 5.
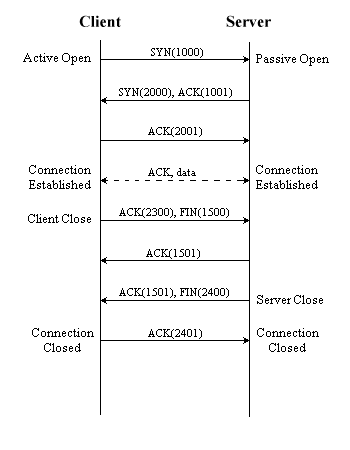
|
I packet filter in senso stretto sono tipicamente
implementati
nei router (anche se al giorno d'oggi esistono apparati anche economici che
implementano già la stateful inspection); l'analisi del pacchetto
avviene
a livello IP (corrispondente al Layer 3, Network, del modello ISO/OSI): sono
essenzialmente 4 i campi che vengono presi in considerazione: indirizzo di
origine
del pacchetto, indirizzo di destinazione, protocollo (tcp, upd, icmp,
isakmp,
esp, ecc), ed eventuali opzioni. Quest'ultimo campo, solitamente, è
vuoto, ma può contenere un flag di source routing, che viene
utilizzato
dal mittente per "scavalcare" le routing tables del destinatario;
in passato,
questo flag è stato spesso utilizzato in alcuni tipi di attacco, per
cui molti firewall droppano di default un pacchetto con questa opzione
attiva
(in caso di linux, il kernel 2.4 ha una apposita opzione modificabile
run-time
mediante il file
/proc/sys/net/ipv4/conf/all/accept_source_route,
parametro che andrebbe posto uguale a zero).
Come è facile capire, le cosiddette
routing
decisions vengono prese valutando se gli indirizzi di provenienza sono
considerati
attendibili per quella particolare destinazione, con quel particolare
protocollo,
ecc. Nel caso di packet filter più evoluti (praticamente tutti, al
giorno
d'oggi), il controllo del pacchetto avviene al Transport Layer (livello 4)
del
modello ISO/OSI: questo implica che, oltre alle informazioni contenute
nell'header
IP (indirizzo origine, destinazione e opzioni), vengono considerate anche le
porte (sia di origine, che di destinazione). In questo modo, è
possibile
filtrare il traffico in base al protocollo utilizzato (http, https, smpt,
ecc),
in quanto molto spesso le applicazioni server aprono porte ben precise.
| Nota: va comunque sempre ricordato che il protocollo TCP/IP non è in grado di garantire l'autenticità dell'indirizzo o della porta di origine contenuti nel pacchetto! Infatti, è possibile costruire dei pacchetti appositamente modificati , in modo tale che l'ip di provenienza risulti falso. Questo tipo di tecnica è alla base del cosiddetto ip spoofing. |
Il vantaggio di questo tipo di firewall è
essenzialmente
l'economicità: infatti, come abbiamo visto, l'analisi dei pacchetti
avviene
tutta a livello 3 o 4 del modello OSI, e questo processo richiede un uso di
risorse (cicli di CPU) molto basso; in più, abbiamo già
accennato
al fatto che molti sistemi operativi dei router (anche i più
economici)
implementano già nativamente questo tipo di soluzioni. Un altro
importante
vantaggio dei packet filter è la loro trasparenza: le
applicazioni
non devono essere scritte in maniera particolare per beneficiare di questo
tipo
di protezione.
Per contro, utilizzando i packet filter un client
che
dall'esterno fa una richiesta ad una applicazione server è a tutti
gli
effetti connesso direttamente al server stesso. In più, a volte la
corretta
configurazione di tali firewall può richiedere una discreta
conoscenza
del funzionamento dei protocolli di rete, al fine di sapere esattamente
quali
porte aprire per consentire le connessioni, senza aprire più porte
del
necessario (vedremo oltre un esempio classico, l'ftp). Per finire, tutto il
sistema decisionale si basa sui dati presenti nell'header del pacchetto:
questo
ha due importantissime conseguenze:
- i dati nell'header possono essere falsificati, creando pacchetti
appositamente
modificati (il cosiddetto spoofing)
- non ho nessun controllo su ciò che è contenuto nel pacchetto
(i dati veri e propri). Ad esempio, una richiesta ad un web server mirata a
sfruttare un buffer overflow del server stesso verrà comunque
lasciata
passare
All'esatto opposto troviamo l'application gateway:
in questo caso, tutte le connessioni verso una macchina posta dietro di esso
non si stabiliscono direttamente con la macchina stessa, bensì con
l'application
gateway. Questo implica che tutte le applicazioni server devono essere
progettate
per supportare questo tipo di connessione; inoltre, ogni specifico servizio
(ftp, telnet, web, ecc) necessita di un proprio proxy (il programma
che
effettivamente si occupa della comunicazione con il servizio
"protetto"). Un
esempio pratico aiuta a chiarire le cose: prendiamo un server web e un
client
che intende visualizzare una pagina del sito; in caso di assenza di
protezione
perimetrale (o in caso questa sia deputata ad un packet filter), il browser
del client si collega al server web per richiedere una pagina; a questo
punto,
il server risponde al client inviando quanto richiesto. In presenza di un
application
gateway, invece, il client si collega a quest'ultimo (a dire il vero, con
l'application
proxy che gestisce il protocollo http) ed effettua a lui la sua richiesta. A
questo punto, è il proxy a collegarsi al web server vero e proprio,
richiedendo
la pagina in questione, per poi inviarla al client come se fosse stato lui
stesso
a generarla.
Come risulta chiaro dall'esempio precedente, il
principale
vantaggio degli application gateway è che non sono possibili
connessioni
dirette tra la rete interna e quella esterna: questo implica che un baco in
una applicazione server non consentirà ad un eventuale attacker di
prendere
diretto possesso della macchina. Inoltre, lavorando a livello Applicazione,
il proxy ha accesso diretto al contenuto del pacchetto, e quindi il
controllo
di accesso può avvenire anche in base al contenuto stesso (vedremo un
importante esempio nel caso di un web server). Infine, tramite un
application
gateway è possibile gestire gli accessi anche tramite autenticazione
(username e password), e non solo in base agli IP di provenienza e
destinazione.
I principali difetti di questo tipo di protezione
perimetrale
sono facilmente intuibili: il carico di lavoro in termini di cicli CPU
è
estremamente maggiore rispetto a quello dovuto ad un semplice packet filter.
Inoltre, come precedentemente detto, tutte le applicazioni server devono
essere
progettate per l'utilizzo del proxy (anche se, a dire il vero, è
già
sul mercato una seconda generazione, "trasparente", di application
pxoxy).
Alcuni autori sostengono che i cosiddetti
"stateful
firewall" si posizionino a metà strada tra il classico packet
filter
e l'application gateway. Personalmente non sono d'accordo con questa
visione:
anche se è certamente vero che i proxy beneficiano dello stato di una
connessione nel processo decisionale, a mio avviso gli stateful firewall (a
volte deviniti anche circuit-level firewall) sono piuttosto una
evoluzione
del classico packet filter.
La stateful inspection è quel processo per
cui
ogni singola connessione autorizzata viene registrata dal firewall in una
apposita
tabella (la cosiddetta connection o state table): oltre all'ip
sorgente e di destinazione, solitamente vengono registrati tanti altri dati,
quali il protocollo, le porte, i flag, i sequence number, ecc. In questo
modo,
è difficile per un hacker potersi inserire in una connessione
stabilita
(il cosiddetto session hijacking). In pratica, ogni volta che un
pacchetto
arriva al firewall, viene verificato se esso fa parte (o è correlato,
come vedremo nel caso dell'ftp) di una connessione precedentemente
stabilita:
in caso affermativo, esso viene lasciato passare senza ulteriori controlli
sulle
catene del firewall stesso, altrimenti subisce la sorte di un normale
pacchetto
in ingresso. Il vantaggio sta nel fatto che la verifica sullo stato è
molto meno impegnativa del controllo "normale", per cui il
firewall risulterà
più performante. Oltre ad una innegabile
questione
di prestazioni, è importante sottolineare che alcuni servizi di rete
(e il file transfer protocol ne è l'esempio per eccellenza)
necessitano
di aprire un secondo canale di comunicazione: se non potessi sfruttare lo
stato
di una connessione, mi troverei a dover permettere le connessioni a tutte le
porte non privilegiate (>1024), quando invece esse devono rimanere aperte
solo per quella determinata connessione. Questo discorso sarà
più
chiaro fra poco.
Vediamo ora di chiarirci le idee analizando il
più
ricorrente degli esempi: il protocollo FTP (File Transfer Protocol).
Soprannominato
in passato "l'incubo dei sistemisti", questo protocollo nacque
appunto
per permettere lo scambio di file; non entreremo ora in merito a
considerazioni
legate alla trasmissione dati in chiaro, all'utilizzo o meno di accessi
anonimi,
ecc. La nostra attenzione si rivolgerà esclusivamente alle tecniche
che
si utilizzano per filtrare, tramite firewall, l'accesso a questo
servizio.
ll protocollo FTP può funzionare in due
modalità,
normale e passivo. Nel primo caso, un client si collega all'ftp
server,
in ascolto sulla porta 21, stabilendo un control channel; nel momento
in cui viene trasferito un file, si crea un secondo canale, detto data
channel,
utilizzato appunto per il trasferimento dati (invio e ricezione file,
visualizzazione
del contenuto di una directory, ecc). Questo secondo canale va da una porta
qualsiasi del client alla porta 20 del server (vedi fig· 5). Mettiamoci ora
nei panni di chi deve scrivere le regole di un packet filter, che deve
permettere
le connessioni ad un ftp server posto "dietro" di esso; in questo
caso, la stateful
inspection non risulta di particolare utilità (so che i sistemisti
più
smaliziati e i security specialist staranno storcendo il naso, a queste
parole... perdonate
la semplificazione a scopo didattico): basterà semplicemente
permettere
tutte le connessioni in ingresso, verso le porte 21 e 20 del server ftp, e
tutte
le connessioni in uscita dalle porte 20 e 21 dello stesso server. Facendo
riferimento
ai dati di fig. 6, vediamo come scrivere le regole per un firewall Netfilter
che protegge un server ftp:
iptables -A FORWARD -p tcp -d 5.6.7.8 --dport 20:21 -j ACCEPT iptables -A FORWARD -p tcp -s 5.6.7.8 --sport 20:21 -j ACCEPT |
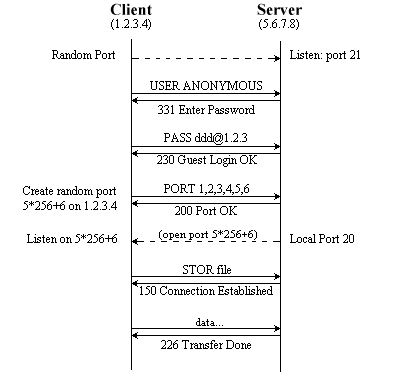
|
Ben differente è il caso dell'ftp in passive mode: in questa modalità il data channel viene creato tra una porta casuale del client ed una altrettanto casuale del server. Non sarà quindi possibile aprire sul firewall la sola porta 20! Affinchè il servizio sia garantito, è necessario consentire la connessione a tutte le porte del server superiori alla 1024esima. In questo modo, però, se sul server è in esecuzione un servizio in ascolto su di una porta non privilegiata (un esempio a caso, Microsoft SQL Server....), non avrò più nessun filtro a proteggere da connessioni non autorizzate. Ed ecco che la stateful inspection dimostra tutta la sua utilità e potenza: potrò esplicitare che le connessioni verso le porte >1024 sono consentite solo se correlate ad una già stabilita (e quindi autorizzata). Tornando all'esempio di prima, utilizzando Netfilter scriverò:
iptables -A FORWARD -p tcp -d 5.6.7.8 --dport 21 -j ACCEPT
iptables -A FORWARD -p tcp -d 5.6.7.8 --dport 1024:65535 -m state \
--state ESTABLISHED,RELATED -j ACCEPT |
Vale la pena di sottolineare la differenza sostanziale di queste due differenti situazioni: senza utilizzare la stateful inspection, sarei costretto a non filtrare in alcun modo le connessioni dirette a porte >1024! Tramite le connection table, invece, il mio packet filter consentirà solamente le connessioni dipendenti da quelle già instaurate.
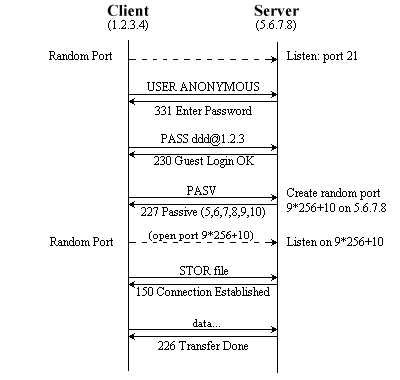
|
L'autoreTommaso Di Donato è
sistemista
Linux (Red Hat Certified Engineer) e Microsoft dal 1998; è stato
dba Oracle presso la PA, nell'ambito del progetto di informatizzazione
dei
Centri Protesi INAIL in Italia. |
|
|
<- SL: Intro - Archivio Generale - Copertina - SL: GNU/Linux e autoloader -> |
|