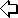

|
|
<- PW: Gosh - Archivio Generale - Copertina - SL: Intro -> |
|
PlutoWare
di Angelo Rodolfo Tomaselli, Andrea Suisani, Matteo Centenaro
L'articolo...YaaCs è un software svilupato in Tcl/Tk, per la gestione e la realizzazione di interviste telefoniche (CATI) e telemarketing, da Demetra, una ditta di Mestre che si occupa di indagini statistiche. Cosa più importante, la ditta ha deciso di rilasciarlo come Free Software; questo articolo presenta l'applicazione e le ragioni che hanno condotto a questa scelta. |
Demetra è la società che ha sviluppato il software. Si occupa di indagini campionarie e sondaggi demoscopici. Le indagini da noi condotte sono di due nature: vis a vis e telefoniche. Tra le due tipologie quella preponderante è la seconda, a cui va aggiunta, anche se minima, un'attività di telemarketing per i nostri clienti (cioè della pubblicità personalizzata via fax o via telefono) che utilizza gli stessi strumenti messi a punto per le indagini telefoniche.
Visto l'aumento del volume di lavoro avvenuto negli ultimi due anni (è sufficiente una rapida scorsa all'indirizzo www.opinioni.net) si è posta l'esigenza di una riorganizzazione dei processi produttivi, nonché la necessità di valutare dei nuovi strumenti che ci permettessero un'efficiente strutturazione del nostro lavoro. Ciò, aggiunto ad una predisposizione del nostro gruppo di lavoro alla "filosofia" del free software, e alle possibilità di crescita professionale (e umana) che questa porta con sé implicitamente, ha fatto si che decidessimo di sviluppare un nostro software per la gestione del core business della società per cui lavoro, e di licenziarlo sotto GPL.
La nostra scelta comunque si fonda anche sulla convinzione che il FS possa costituire un'ottima alternativa ai software proprietari, sia che si parli di sistemi operativi o di applicativi più in generale. L'esperienza di un anno di core business basato sul FS (GNU\Linux, PostgreSQL ecc ecc.) ne sono la prova. Stabilità, affidabilità, e un'ottimo rapporto qualità/costi ci hanno permesso di lavorare bene e in maniera efficace.
In realtà il primo passo di questa "rivoluzione" è stato l'adottare strumenti free software (GPL) anche per quella parte del sistema informativo aziendale non direttamente orientato allo svolgimento delle indagini telefoniche. Infatti si è passati da un ambiente totalmente implementato su software proprietari ad un sistema misto (proprietario/free-software) dove la parte del free-software è ora preponderante. Inoltre visti i risultati ottenuti attraverso questi strumenti free software abbiamo pianificato una migrazione definitiva verso questi sistemi con l'obiettivo di ridurre al minimo l'adozione di sistemi "chiusi". Attualmente questo step di sviluppo aziendale rimane ancora sulla carta, ciò è dovuto essenzialmente ad una scarsa disponibilità di una risorsa fondamentale, il tempo, e alla, relativa, complessità del processo di migrazione dovuto alla necessità di mantenere alcune compatibilità con i nostri clienti che per la maggior parte lavorano con software specialistici proprietari che sono pensati per lavorare sotto sistemi Windows.
Attualmente il nostro sistema informativo è composto da due LAN isolate dall'esterno (cioè senza accesso a internet attraverso connessioni permanenti e senza offrire servizi “online”). Una è composta da 3 workstation (di cui una è BDC) win98 e un server winNT 4.0 che fornisce i servizi di PDC, DNS, PROXY etc etc a i client di questa rete. La seconda è composta da più di 20 macchine ed interamente basata su software free software: sistema operativo GNU/Linux (vendor SuSe), RDBMS PostgreSQL, file system distribuito NFS, NIS, fax server HylaFAX, emulatore dos DosEmu.
La strutturazione di quest'ultima LAN è ancora molto semplice. Esiste un macchina dove praticamente risiedono tutti i servizi presenti sulla rete (RDBMS, NFS, NIS, fax server); le restanti stazioni si dividono in due tipologie: workstation dedicate agli operatori/intervistatori telefonici, ed altre che sono dedicate allo sviluppo e all'amministrazione del sistema. Gli utenti accedono ai servizi di rete dai vari client con account definiti sul server e condivisi tramite NIS (network information service). Le home di ogni utente sono invece esportate dal server ai client tramite NFS.
Ora che l'ambiente in cui il nostro progetto si sviluppa è stato descritto passiamo al nocciolo della questione: "cosa fa" il nostro software e come lo abbiamo sviluppato. In sintesi YaaCs è un sistema, sviluppato in Tcl/Tk (lato client tramite un tool di sviluppo visuale open source, vTcl), per la gestione e la realizzazione di interviste telefoniche e telemarketing. Gestisce la trasmissione di fax centralizzata attraverso l'utilizzo del fax-server Hylafax, e salva tutti i dati relativi alla procedura di contatto su un database PostgreSQL. Semplifica il lavoro degli intervistatori/operatori che "ricavano" i dati di ogni contatto su una comoda e funzionale interfaccia grafica (GUI). Facilita il monitoraggio delle indagini / telemarketing fornendo diverse informazioni all'amministratore del progetto sul numero di contatti portati a termine, quelli che mancano per concludere il progetto, il numero di nominativi ancora disponibili e così via.
Prima di addentrarci in una descrizione dettagliata è bene fare un ulteriore premessa. Il nostro software è stato ideato per la gestione e l'automatizzazione delle procedure coinvolte in una “campagna telefonica”, sia questa un'indagine statistica rivolta alle aziende o alla popolazione, o anche un progetto di telemarketing telefonico. Le funzioni di YaaCs sono, per ora, distanti da quelle di un sistema CATI1 (computer assisted telephone interviewing) completo. Infatti un sistema di questo tipo si occupa della gestione (amministrazione) di un progetto (indagine) – creazione, definizione del piano campionario, estrazione dei nominativi telefonici georeferenziati, controllo del rispetto delle “quote” campionarie a indagine in corso (e conseguente modifica della funzione di probabilità che regola l'estrazione dei contatti telefonici) – e della registrazione in formato elettronico dei dati relativi alle interviste fatte dagli operatori (le risposte dati dagli intervistati al questionario) – in questo blocco ricadono anche gli strumenti per l'informatizzazione del questionario (e appunto la registrazione delle interviste su supporto informatico).
Allo stato attuale di sviluppo YaaCs copre “solamente” l'amministrazione di un progetto di contatto telefonico e la gestione del flusso delle chiamate. Nella nostra realtà aziendale la registrazione delle interviste e l'informatizzazione del questionario è implementata attraverso una vecchia versione per MSDOS di un CATI system e dall'emulatore dos DosEmu. L'implementazione di questa specifica soluzione per la registrazione dei dati esula dallo scopo di queste pagine, quindi verrà tralasciata.
Entrando nello specifico, possiamo dividere il nostro software in due blocchi; il primo è dedicato agli utenti (operatori telefonici) di cui fanno parte i client attraverso i quali gli utenti accedono ai servizi che sono messi a disposizione lato server dal sistema, permettendo cioè la condivisione dei nominativi da chiamare nell'ambito di un dato progetto, tramite l'accesso concorrente al database ove questi sono memorizzati. A questo blocco appartengono anche i tool messi a disposizione per l'amministrazione di un dato progetto: creazione, cancellazione di un'indagine, modifica dei parametri relativi ad un'indagine (struttura campionaria, algoritmo di estrazione etc etc).
Il secondo blocco rappresenta il cuore del nostro pacchetto. Questo è “composto” dal database PostgreSql (dove sono registrati i numeri telefonici georeferenziati) inteso come schema del database, dati e store procedures sviluppate in PL/Pgsql2 attraverso le quali vengono gestite tutte le operazioni ripetitive che risentono pesantemente (in senso positivo) dell'uso della cache per il query plans dei tasks SQL che la procedura deve eseguire. Di queste procedure / funzioni, adottate anche per tutti quei tasks ripetitivi che richiedono una parametrizzazione, viene fatto un pesante uso da entrambi i client (per l'amministratore e per gli operatori) sopra presentati.
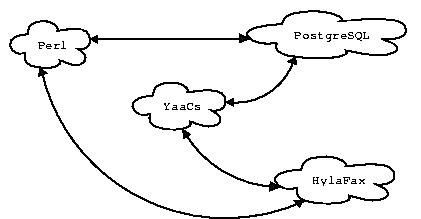
Figura 1. Interazione tra le varie componenti del software
L'interazione tra questi due blocchi avviene come segue: tramite i client (sviluppati in Tcl, vedi nuvoletta YaaCs, di fig.1) l'amministratore e gli operatori telefonici inviano le richieste (stringhe contenti query SQL via TCP/IP) a l'RDBMS. Queste richieste sono poste tramite l'uso della libreria libpgtcl (un pacchetto che permette l'interfacciamento a PgSql dai front-end sviluppati in Tcl) Sempre tramite i client gli operatori hanno la possibilità di appoggiarsi ad un fax-server per l'invio di fax; una volta inviata la richiesta hylaFax (il nostro fax-server) comunica l'avvenuto accodamento del job (oppure l'eventuale messaggio d'errore).
Per avere un servizio di inoltro fax robusto e facile da gestire nei casi in cui ci siano dei problemi nell'invio dei fax (solitamente dovuti a problemi di incompatibilità di protocollo di trasmissione, macchine fax datate ecc. ecc.) è stata sviluppata una rudimentale (e in fase di riprogettazione) utility in perl, che individua nei log del fax-server i numeri di fax relativi alle trasmissioni con esito negativo, e tramite il modulo DBI (Data Base Interface) DBD::Pg3 accede al database PostgreSql e aggiorna il record corrispondente al contatto relativo al numero di fax, in maniera che l'operatore sia messo al corrente del mancato inoltro. In questo modo si potrà accertare presso il destinatario la causa del problema e porvi soluzione.
La struttura del database, per la parte riguardante un generico progetto/indagine, implica un disegno che, tradotto in uno schema entità-relazione (vedi fig.2), coinvolge le diverse entità (tabelle) qui elencate:
|
Nome tabella |
Significato |
|
anagrafica |
Registra i dati anagrafici degli intervistati |
|
appuntamenti |
Gestisce gli appuntamenti che gli intervistatori prendono con gli intervistati |
|
indagini |
Registra tutti i dati relativi alle varie indagini (in corso e non) |
|
nominativi |
Lista di tutti i numeri di telefono italiani georeferenziati |
|
stato_contatto |
Lista dei possibili stati del contatto per una indagine rivolta a persone |
|
stato_contatto_az |
Lista dei possibili stati del contatto per una indagine rivolta ad aziende |
|
<nome_indagine>_teorica |
Struttura campionaria assegnata all'indagine denominata <nome_indagine> |
|
titolo_studio |
Lista dei possibili titoli di studio |
|
<nome_indagine> |
Registra i numeri di telefono e i dati relativi ai nominativi da contattare per una data indagine |
Tabella 1. Tabelle coinvolte nello svolgimento di un progetto e loro significato
Nella tabella indagini sono riportati tutti i dati relativi ad una data indagine, il titolo (<nome_indagine>), il nome della tabella in cui sono registrati i nominativi da contattare, e diversi parametri che regolano la procedura di contatto (tempo di attesa per la chiamata i in base all'esito della chiamata i-1), il path dei documenti da spedire via fax, se l'indagine è in corso etc. etc. In questa tabella è presente una tupla per ogni indagine in corso (e anche per quelle terminate se non sono state eliminate definitivamente) nel sistema. Ad ogni tupla è associata una tabella in cui sono contenuti i nominativi da contattare per il progetto considerato, una tabella <nome_indagine>_teorica dove è riportato il disegno campionario dell'indagine, su cui si baserà il controllo “run time” delle quote campionarie; inoltre, su di essa si fonda la definizione della funzione di probabilità per le estrazioni necessarie a ripopolare la tabella <nome_indagine> una volta che i nominativi da chiamare (liberi) siano finiti, senza però aver raggiunto la quota di interviste da fare per considerare l'indagine (o il progetto) concluso.
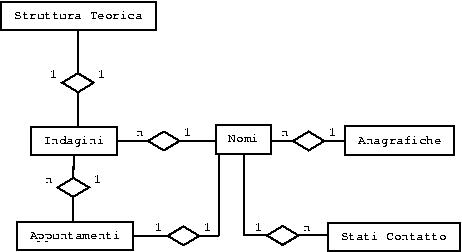
Figura 2. Schema ER per la memorizzazione dei dati riguardanti un generico progetto/indagine.
Nel processo di contatto sono coinvolte altre entità comuni a tutte le indagini definite nel database. Stiamo parlando della tabella appuntamenti, della tabella anagrafica e della tabella stato_contatto (vedi tab.1). Nella tabella appuntamenti vengono registrati gli appuntamenti presi dagli operatori; tra questa e la tabella <nome_indagine> esiste una relazione uno a uno. Infatti, ad un dato contatto presente nella tabella <nome_indagine>, al tempo t0, corrisponde, al massimo, un solo appuntamento. La tabella appuntamenti è usata anche per mettere in attesa di richiamo quei nominativi per cui la chiamata precedente ha avuto come risultato uno dei seguenti stati:
busy-occupato (il contatto viene ripresentato all'intervistatore dopo X1 minuti);
no answer-libero (il contatto viene ripresentato all'intervistatore dopo X2 minuti);
answering machine-segreteria (il contatto viene ripresentato all'intervistatore dopo X3 minuti);
schedule callback-appuntamento (possibilità di gestione appuntamento con richiamo automatico);
SendFax-Faxspedito (possibilità di invio automatico di fax al contatto, completo di referente-oggetto. Gestione dei fax inviati con notifica. Richiamo per verifica dopo X4 minuti );
Dove i parametri X1, X2, X3, X4 possono essere cambiati in ogni momento tramite il tool di amministrazione, e sono registrati come già descritto in precedenza nella tabella indagini. Per i seguenti esiti invece il contatto non viene più ripresentato all'intervistatore.
Fax-Rispondefax (a quel numero di telefono risponde un fax; il contatto non viene più ripresentato all'intervistatore);
non working number-inesistente (il contatto non viene più ripresentato all'intervistatore);
refuse-rifiuta (il contatto non viene più ripresentato all'intervistatore);
over quota-non quota (il contatto non viene più ripresentato all'intervistatore);
complete-risponde (i dati anagrafici vengono registrati in una apposita tabella senza dati sensibili ed il contatto non viene più ripresentato all'intervistatore);
Quando un operatore tramite la sua GUI (client) richiede al server RDBMS un nuovo nominativo da contattare, prima viene verificata nella tabella appuntamenti la presenza di un appuntamento (implicito, ad es .per libero come risultato alla chiamata precedente, o esplicito) da evadere; nel caso non ci sia, viene selezionato il primo nominativo libero dalla tabella <nome_indagine>. L'accesso a entrambe queste due tabelle è definito in maniera da garantire la consistenza dei dati, tramite un meccanismo che gestisce l'accesso concorrente implementato in PostgreSql, e denominato “row-level lock”. Questo fa sì che i dati relativi ad un nominativo selezionato da un dato intervistatore non venga selezionato e modificato da altri mentre si sta procedendo al contatto con la procedura di chiamata.
La tabella stato_contatto invece è stata pensata al fine di ottenere una parametrizzazione dei possibili stati in cui può sfociare una chiamata. Comunque questa al momento è solo abbozzata in quanto i client per gli operatori sono stati sviluppati in una maniera tale da essere vincolati pesantemente ai dati presenti in questa tabella. È nelle nostre intenzioni infatti ripensare la porzione di codice che si occupa della gestione della registrazione dello stato del contatto e del disegno stesso della tabella, introducendo un livello di astrazione (concetto di meta-stati) che ci svincoli da un classificazione troppo rigida della tipologia a cui appartiene la chiamata.
Passiamo ora ad una delle parti più interessanti del nostro software: l'estrazione dei nominativi georeferenziati secondo la funzione di probabilità definita dal disegno campionario. Per descrivere questa funzione prendiamo ad esempio un indagine statistica sulla popolazione (i famigerati sondaggi d'opinione). La maggior parte delle indagini statistiche telefoniche (e non) rivolte alla popolazione, nella pratica seguono un piano di campionamento stratificato4. Per poter estrarre dalla tabella dei numeri telefonici totale (circa 18 milioni di tuple) bisogna caratterizzare le unità statistiche (i nostri numeri di telefono appunto) geograficamente, cioè georeferenziare. La classificazione da noi adottata (risultato di un compromesso tra possibile generalizzazione del piano di campionamento e criteri di fattibilità) arriva a considerare come unità geografica minima il comune (la classificazione delle unità comunali è quella data dall'ISTAT; ad ogni comune italiano è assegnato un codice che è composto da un codice provincia concatenato ad un progressivo per ogni comune). Grazie a questa georeferenziazione siamo in grado di collocare ogni numero telefonico, presente nel nostro database, a livello comunale, provinciale e regionale.
Il processo che popola la tabella relativa ad un'indagine al momento della sua definizione (estrazione) è regolato dalla struttura dell'entità <nome_indagine>_teorica che tipicamente si presenta come:
create table <nome_indagine>_teorica (
cod_prov integer;
num_capo integer;
num_non_capo integer;
)
La struttura di questa tabella definisce un campionamento stratificato, dove ogni strato è definito da un codice provincia e dalla variabile capoluogo. Ogni riga di questa tabella definisce due strati; il primo raggruppa tutti i numeri telefonici con codice comune appartenente alla provincia indicata da cod_prov e con variabile capoluogo pari a 1; il secondo i comuni appartenenti alla provincia ma con variabile capoluogo pari a 0 (comuni non capoluogo di provincia). Al momento della creazione dell'indagine la tabella relativa verrà popolata con un numero di record pari a
select sum(num_capo+num_non_capo)
from <nome_indagine>_teorica;
che saranno estratti dalla tabella dei numeri totale (nominativi; vedi tab.1) secondo la funzione di probabilità definita implicitamente dai dati presenti in <nome_indagine>_teorica. L'estrazione all'interno di uno strato è casuale5 in maniera da non concentrare i numeri estratti in una determinata zona geografica all'interno dello strato.
Le estrazioni successive alla prima effettuata per popolare la tabella introducono una ridefinizione della funzione di probabilità descritta dalla tabella <nome_tabella>_teorica. Questa ridefinizione individua le nuove numerosità da estrarre per ogni strato ponderando la differenza tra la numerosità da fare per ogni strato e quella raggiunta al momento dell'estrazione. Questa ponderazione è basata su un coefficiente definito come l'inverso del tasso di copertura, calcolato al momento dell'estrazione.In sintesi per lo strato i-esimo la nuova numerosità sarà pari a :
N(i) = (N_teo(i) – N_eff(i)) * (N_eff(i) / N_teo(i) )-1
In questo modo è possibile correggere la funzione di probabilità che regola l'estrazione “in corso”, reperendo più nominativi negli strati dove abbiamo una tasso di risposta più basso, e garantendo quindi una convergenza alla numerosità prevista in maniera omogenea rispetto agli strati.
Queste funzionalità6 sono accessibili tramite il client di amministrazione assieme a quelle del controllo delle quote campionarie, che permettono di avere una visione del progresso dell'indagine.
È previsto anche il controllo di quote campionarie non territoriali. Infatti se il disegno campionario prevede il rispetto di quote definite dalle variabili genere e età dell'intervistato è possibile monitorare anche queste.Le operazioni necessarie a utilizzare questo ulteriore strumento sono descritte nella documentazione inclusa nel progetto e disponibile all URL http://yaacs.sourceforge.net.
2.4 YaaCs gestisce anche gli intervistatori
Nel pacchetto è presente anche un tool per la gestione e l'organizzazione degli operatori, che si interfaccia con un database, separato rispetto a quello usato per la gestione dei nominativi telefonici, in cui sono registrati tutti i dati utili alla gestione, al reperimento e “all'amministrazione” degli intervistatori. Nello schema in fig.3 è riportato lo schema entità relazione di questo data base.
Figura 3. Schema ER per la memorizzazione dei dati riguardanti la gestione gli
intervistatori.
Tramite questo tool è possibile associare un intervistatore ai progetti che stanno per iniziare e organizzare in maniera efficace il reperimento di questi. Nella tabella intervistatori è presente anche un attributo che indica un punteggio assegnato all'operatore il cui calcolo per adesso non è automatizzato, ma che nelle versioni successive sarà possibile definire automaticamente sulla base
delle prestazioni fornite in termini di produttività e di qualità del dato7. Tramite la tabella statistiche, dove vengono registrate tutte le azioni degli intervistatori, è possibile tenere sotto controllo tutti i tempi necessari all'operatore per compire le diverse azioni: fare un intervista, prendere un appuntamento (esplicito o implicito), spedire un fax ecc. ecc. È possibile anche gestire il reperimento degli intervistatori / operatori per effettuare i pagamenti dovuti.
Allo stato attuale la tabella statistiche non è ancora presente nella versione scaricabile dall'homepage del progetto, la sua implementazione è in fase di testing, come lo sono l'elaborazione di altre funzioni ad essa associate, quali il calcolo delle ore lavoro per ogni intervistatore associate ai diversi progetti a cui ha partecipato e l'eventuale calcolo del compenso dovuto.
Le linee di sviluppo si possono dividere in due filoni. Uno riguardante l'integrazione di YaaCs con altri software free software, il secondo invece più votato allo sviluppo del pacchetto in sé. Per quel che riguarda il primo filone gli obiettivi con priorità più alta sono:
L'integrazione con un software CAWI (computer assisted web interviewing) – CATI. In questo modo riusciremo ad ottenere un pacchetto per le indagini statistiche completo, che gestisca anche l'informatizzazione e la registrazione dei dati ottenuti dalle interviste.
Integrazione con sql-ledger8 per la gestione “amministrativa / finanziaria” dei progetti
Integrazione con il software statistico R9 per garantire una maggiore flessibilità nel controllo delle quote del disegno campionario.
Integrazione con un qualche software (da valutare) per la generazione di report human-readble per l'attività degli intervistatori e per il progresso dell'indagine (n. accessi, tempi, quote)
Per quel che riguarda lo sviluppo interno del pacchetto ciò che il nostro gruppo di lavoro ritiene prioritario riguarda:
Introduzione di un livello di priorità per gli appuntamenti (già sviluppato e in fase di testing) in questo modo un appuntamento esplicito è più importante di uno implicito (es. libero o occupato)
Generalizzazione dell'algoritmo di estrazione sia per le indagini rivolte alle aziende che per quelle rivolte alla popolazione. Introducendo così un livello di astrazione che svincoli l'utilizzatore dal legame troppo forte, ora presente, al tipo di disegno campionario che attualmente YaaCs è in grado di supportare.
Miglioramento della gestione del mancato invio dei fax.
Introduzione di un livello maggiore di sicurezza nell'ottica di un ambiente di lavoro che non sia una LAN isolata (che è l'ambiente in e per cui YaaCs è stato sviluppato), ma vada verso un ambiente “web/oriented”, pensato anche per un servizio di self-made survey a chi ne abbia bisogno.
Parametrizzazione della copertina del fax da inviare basata su l'utilizzo di template in latex facilmente personalizzabili.
YaaCs è un progetto giovane ed ha ancora molta strada davanti a se per poter migliorare ed essere generalizzato in modo da essere il più possibile flessibile. Dalla sua parte, però, ha già molte ore di utilizzo all'interno di Demetra ciò ha contribuito e contribuirà notevolmente alla sua maturazione. Chiunque sia interessato e voglia partecipare al progetto, come nella miglior tradizione del software Open Source, é ben accetto e può contattarci tramite mail (info@cawi.it) oppure attraverso il sito ufficiale di YaaCs (http://yaacs.sourceforge.net).
Attualmente YaaCs è alla versione 0.1 (la prima), questa richiede come prerequisiti PostgreSQL, HylaFAX, perl , Tcl/Tk10, ed è stato sviluppato su piattaforma hardware intel pc con le seguenti specifiche di sistema:
Sistema Operativo:GNU/Linux
Kernel 2.4.9
Specificatamente le versioni di questi software compatibili con YaaCs sono
PostgreSQL ver 7.1.1 (vedi www.postgresql.org)
Hylafax ver 4.1.1
Tcl/Tk ver 8.3
Perl ver 5.6.0
La prossima versione di YaaCs (ver 0.2) è prevista per inizio giugno 2002 e sarà basata sulle versioni recenti di PostgreSQL (ultima ver. 7.2.1, 2 aprile 2002) e HylaFAX (ultima ver.4.1.2, 12 aprile 2002), mantenendo comunque la compatibilità con quelle attuali.
Sono presenti numerosi screenshot di YaaCs all URL http://yaacs.sourceforge.net/screenshot.htm
1I sistemi CATI si sono sviluppati all'inizio degli anni '70 con la diffusione del telefono (in alcuni paesi la copertura telefonica negli anni '70 è arrivata al 90%). Le funzioni di scheduling manuali ed il questionario cartaceo sono diventate dei sistemi informatizzati. Decine di sistemi CATI si sono sviluppati dagli anni '70 ad oggi con potenzialità differenti. La funzione dell'intervistatore è sostanzialmente cambiata in quanto i sistemi CATI le effettuano automaticamente.
2 Linguaggio procedurale (PL) “lato server” messo a disposizione, tra gli altri, dal RDBMS PostgreSql.
3 Vedi http://dbi.perl.org/cgi/moduledump?module=DBI
4 Se l'universo della ricerca non è omogeneo per avere una minor variabilità si può ricorrere al campionamento stratificato, combinando più campioni casuali semplici indipendenti e scelti in appropriate proporzioni, da strati omogenei, in una popolazione eterogenea. Ad esempio gli strati potrebbero essere costituiti dalle aree territoriali, dal genere, dall'età o dalla professione.
5 La casualizzazione è ottenuta attraverso la clusterizzazione della tabella nominativi. Vedi http://www.postgresql.org/idocs/index.php?sql-cluster.html. Quando una tabella viene clusterizzata viene fisicamente riordinata sulla base di un indice indicato nella sintassi del comando cluster. Nel nostro caso l'indice è definito sui campi cod_prov, capoluo, rand (un double precision casuale compreso tra 0 e 1).
6 Estrazione, definizione del disegno campionario ecc. ecc.
7 La qualità del dato ottenuto da interviste telefoniche è garantito da diversi parametri, alcuni dei quali indipendenti dall'operato dell'intervistatore (es. qualità del questionario, lunghezza del questionario, facilità d'uso degli strumenti per effettuare l'intervista). In questo caso si fa riferimento a quegli aspetti direttamente riconducibili a come l'operatore somministra il questionario all'intervistato (es. chiarezza espositiva, standardizzazione della lettura del questionario).
8 Vedi www.sql-ledger.org
9 Software statistico, nato come clone free software di S-plus, vedi www.r-project.org
10 Per quel che riguarda PostgreSQL un'installazione completa standard lato server garantisce i requisisti necessari al funzionamento, lato client invece è necessaria unicamente la presenza della libreria libpgtcl. Anche per HylaFAx un installazione standard lato server garantisce un corretto funzionamento (dopo gli opportuni settings), lato client non occorre installare il pacchetto nella sua totalità, si può omettere la compilazione, o l'installazione, dei binari relativi al server side (make installClient).
Gli autoriAngelo Rodolfo Tomaselli (detto Vladi) è diplomato presso ITIS Zuccante di Mestre (indirizzo informatico), laureato in Scienze Statistica presso l'università di Padova (1986). A 22 anni crea una cooperativa che si occupa di ricerche statistiche assieme ad altri studenti universitari. Monotematico nell'attività lavorativa: informatizzazione di questionari nelle indagini statistiche. Attualmente è il socio di Demetra sas. Approda a Linux grazie a Suisani. |
|
Andrea Suisani diplomato presso ITIS "E.Barsanti" di Castelfranco Veneto (indirizzo informatico, 1994), laureato in Scienze Statistiche presso l'università di Padova (1999). Nel 1997 comincia a interessarsi al mondo di GNU/Linux. Lavora a Demetra dal novembre 2000 occupandosi di supervisione delle indagini statistiche CATI, amministrazione di sistema/rete e sviluppo di YaaCs. |
|
Matteo Centenaro diplomato nel 2000 all'Istituto Tecnico Industriale Statale "C. Zuccante" di Mestre. Attualmente iscritto al secondo anno della laurea in Informatica presso la facoltà di Cà Foscari (Venezia). Si occupa di amministrazione di sistema e dello sviluppo di YaaCs presso Demetra dove lavora da più di un anno e dove ha fatto il suo felice incontro con il mondo OpenSource. |
La societàDemetra è una società che si occupa di sondaggi di opinione e di ricerche di mercato. Per fare un esempio è sufficiente leggere il Gazzettino di Venezia del lunedì: troverete il sondaggio sulle opinioni dei cittadini del Nordest da oramai due anni gestita da Demetra. |
|
|
<- PW: Gosh - Archivio Generale - Copertina - SL: Intro -> |
|