mdw@cs.cornell.eduPerché questa seccatura?
Perché si deve imparare la riga di comando ad ogni costo? Bene, lasciate che vi racconti una storia. Qualche tempo fa abbiamo avuto un problema dove lavoro. C'era un disco condiviso su uno dei nostri file server che era sempre pieno. Non voglio fare riferimento al fatto che questo sistema operativo proprietario non supporta le quote utente, questa è un'altra storia. Ma il server continuava a rimanere pieno costringendo le persone a interrompere il loro lavoro. Uno degli ingegneri informatici della nostra compagnia aveva impiegato una giornata per scrivere un programma in C++ che potesse scorrere le directory di tutti gli utenti, sommare lo spazio su disco che stavano utilizzando e creare una lista dei risultati. Poiché ero obbligato a utilizzare il SO proprietario mentre ero al lavoro, ho installato Cygwin, un ambiente a riga di comando simile a quello di Linux che funziona su di esso. Quando sono venuto a conoscenza del problema, ho realizzato che potevo fare tutto il lavoro che aveva fatto questo ingegnere con questa unica riga:
du -s * | sort -nr > $HOME/resoconto_spazio.txt
Le interfacce grafiche (GUI) sono utili per molti compiti, ma non sono adatte a "tutti" i compiti. Ho scoperto da tempo che molti computer oggi non utilizzano la corrente elettrica. Invece sembrano essere mossi dal movimento "pompante" del mouse! I computer sono stati pensati per liberarci dal lavoro manuale, ma quante volte vi sarà capitato di svolgere compiti che pure il computer era in grado sicuramente di svolgere da solo, e invece avete finito col farlo voi, tramite un noioso lavoro di mouse? Punta e clicca, punta e clicca.
Una volta ho sentito un autore rimarcare che quando si è bambini si usa un computer per guardare le figure. Quando si cresce si impara a leggere e a scrivere. Benvenuti al vostro corso di alfabetizzazione informatica. Adesso cominciamo a lavorare.
© 2000-2014, William Shotts, Jr. Verbatim copying and distribution of this entire article is permitted in any medium, provided this copyright notice is preserved. Linux® is a registered trademark of Linus Torvalds.
Traduzione, aggiornamento ed adattamenti in Italiano a cura di Hugh Hartmann hhartmann@libero.it e Vieri Giugni v.giugni@gmail.com. Revisione a cura di Fabio Teatini teafab@pluto.it e Marco Curreli marcocurreli@tiscali.it
Per dirla semplicemente, la shell è un programma che
prende i propri comandi dalla tastiera e li trasmette al sistema operativo
per l'esecuzione. Ai vecchi tempi era l'unica interfaccia utente disponibile
su un computer UNIX. Attualmente, in aggiunta alle interfacce a riga di
comando (CLI) come la shell, disponiamo di interfacce utente grafiche
(GUI).
Sulla maggior parte dei sistemi Linux, un programma chiamato Bash funziona da programma di shell. Bash è l'acronimo di Bourne Again SHell, versione avanzata dell'originale shell sh, scritta da Steve Bourne. Su un tipico sistema Linux ci sono diversi programmi shell aggiuntivi, tra i quali: ksh, tcsh e zsh.
Sono programmi chiamati "emulatori di terminale", che aprono una finestra e permettono di interagire con la shell. C'è un gruppetto di emulatori di terminale che si possono utilizzare. La maggior parte delle distribuzioni Linux ne forniscono diversi, come: xterm, rxvt, konsole, kvt, gnome-terminal, nxterm, e eterm.
Probabilmente, il vostro Window Manager (WM) ha un suo modo di eseguire i programmi da un menù. Guarda nell'elenco di programmi per trovare qualcosa che somigli a un programma di emulazione di terminale. In KDE si possono trovare "konsole" e "terminal" nel menù Utilità. In GNOME si può trovare "xterm a colori", "terminale regolare" e "gnome-terminal" nel menù Applicazioni-Strumenti di sistema. Potete avviare tutti i terminali che volete per giocarci. Benché gli emulatori di terminale siano tanti, fanno tutti la stessa cosa: danno accesso a una sessione di shell. Probabilmente svilupperete una preferenza per uno di essi, basata sui differenti "orpelli" che ognuno fornisce.
Bene, adesso proviamo a digitare qualcosa. Aprite una finestra di terminale. Dovresti vedere un prompt di shell che contiene il vostro nome utente e il nome della macchina seguito dal simbolo del dollaro. Qualcosa come questo:
[io@linuxbox io]$
Eccellente! Ora digitate alcuni caratteri privi di senso e premete il tasto Invio.
[io@linuxbox io]$ kdkjflajfks
Se tutto è andato bene dovreste aver ottenuto un messaggio di errore in cui si segnala che il comando non è stato capito:
[io@linuxbox io]$ kdkjflajfks
bash: kdkjflajfks: command not found
Stupendo! Ora premete il tasto freccia su. Guardate come riappare il nostro precedente comando "kdkjflajfks". Proprio così: abbiamo lo storico dei comandi. Premete il tasto freccia giù e otterrete nuovamente la riga vuota.
Richiamate il comando "kdkjflajfks" utilizzando se necessario il tasto freccia su. Ora provate i tasti freccia sinistra e destra. Potete posizionare il cursore del testo ovunque sulla riga di comando. Questo permette di correggere facilmente gli errori.
|
Non avrete mica fatto il login come utente root, vero?
Se l'ultimo carattere del prompt della shell è un # invece di un $, state operando come il super utente. Questo significa che avete i privilegi di amministrazione (del sistema). Questo può essere potenzialmente pericoloso, dato che si può eliminare o sovrascrivere qualsiasi file del sistema. A meno che non sia assolutamente necessario avere i privilegi di amministrazione, non operate come super utente. |
Anche se la shell è un'interfaccia a riga di comando, per svariate cose si può utilizzare anche il mouse.
Oltre a usare il mouse per spostarsi avanti e indietro attraverso il contenuto della finestra del terminale, è possibile copiare il testo con il mouse. Trascinate il mouse sopra qualche parte di testo (per esempio giusto qui su "kdkjflajfks" nella finestra del browser) tenendo premuto il pulsante sinistro. Il testo dovrebbe risultare evidenziato. Ora spostate il puntatore del mouse nella finestra del terminale e premete il pulsante centrale (in alternativa, potete premere i tasti destro e sinistro contemporaneamente, se state lavorando su un tappettino tattile [touch pad]). Ora, il testo che avete evidenziato dovrebbe essere stato copiato sulla riga di comando.
Quando avete installato il sistema linux e il suo window manager (molto probabilmente Gnome o KDE), esso è stato configurato per comportarsi più o meno come quel sistema operativo proprietario.
In particolare, forse la sua politica di gestione del focus è impostata sullo schema "clicca per dare il focus". Questo significa che per ottenere il focus su una finestra (ossia farla diventare attiva) si deve premere il pulsante sinistro su di essa. Ciò è contrario al tradizionale comportamento delle finestre in X. Dovreste prendere in considerazione la l'alternativa di impostare le politiche di focus allo schema "focus segue il mouse". Questo renderà la funzionalità di copia del testo delle finestre di X molto più facile da usare. All'inizio sembrerà strano che le finestre non passino in primo piano quando ottengono il focus (per far questo si deve premere il pulsante sinistro sulla barra del titolo), ma poi apprezzerete il fatto di poter lavorare su più di una finestra contemporaneamente senza avere la finestra attiva che nasconde le altre. Provate a farci un po' di esperienza con il giusto impegno; penso che vi piacerà. Potete trovare questa impostazione tra gli strumenti di configurazione del window manager.
In questa lezione presenterò i primi tre comandi: pwd (print work directory), cd (change directory) e ls (elenca file e directory).
Se non avete mai lavorato prima con l'interfaccia a riga di comando, dovrete prestare molta attenzione a questa lezione, fino a quando i concetti che si apprenderanno non saranno diventati un po' più familiari.
Proprio come quel sistema operativo proprietario, i file di un sistema Linux sono sistemati in qualcosa che è chiamato struttura gerarchica delle directory. Questo significa che le directory (chiamate 'cartelle' in altri sistemi) sono organizzate a forma di albero e possono contenere file e altre directory. La directory principale è chiamata la directory root. La directory root contiene file e sottodirectory, che contengono altri file e sottodirectory, e così via.
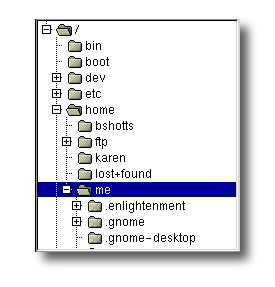
La maggior parte degli ambienti grafici odierni include un programma di gestione dei file per vedere e manipolare il contenuto del file system. Vedrete spesso il file system rappresentato in questo modo:
Una differenza importante tra quel sistema operativo proprietario e Unix/Linux, è che Linux non associa lettere ai dischi. Mentre le lettere dei dischi dividono il file system in una serie di alberi differenti (uno per ogni disco), Linux ha sempre un singolo albero; i dispositivi di memorizzazione differenti sono rappresentati da rami differenti dell'albero, ma l'albero è sempre uno solo.
Dato che un'interfaccia a riga di comando non può fornire rappresentazioni grafiche della struttura del file system, deve avere un modo differente di rappresentarlo. Immaginate l'albero del file system come se fosse un labirinto, e immaginate di esserci dentro. In un dato momento vi trovate in una specifica directory di cui potete vedere i file, il percorso alla sua directory genitrice, e il percorso alle sottodirectory.
La directory in cui vi trovate è chiamata la directory
di lavoro. Per trovare il suo nome, usa il comando pwd.
[io@linuxbox io]$ pwd
/home/io
All'inizio, quando entrate in un sistema Linux, la directory di lavoro è impostata alla vostra directory home. Questa è la vostra directory personale in cui mettere i vostri file. Nella maggior parte dei sistemi Linux, la directory home personale sarà chiamata /home/nome_utente, ma in generale potrebbe assumere qualsiasi altro nome, a seconda dei capricci dell'amministratore di sistema.
Per ottenere una lista dei file presenti nella directory di lavoro,
si usa il comando ls.
[io@linuxbox io]$ ls
Desktop Xrootenv.0 linuxcmd
GNUstep bin nedit.rpm
GUILG00.GZ hitni123.jpg nsmail
Nella prossima lezione tornerò a parlare ancora di ls. Ci sono un po' di cose divertenti che si possono fare con ls, ma prima devo parlare un po' dei "percorsi" e delle "directory".
Per cambiare la vostra directory di lavoro (cioè la vostra posizione nel labirinto) potete usare il comando cd. Per fare questo, digitate cd seguito dal percorso (pathname) della directory desiderata. Un percorso è la strada da prendere attraverso i rami dell'albero per raggiungere la directory voluta. I percorsi possono essere specificati in due modi differenti: percorsi assoluti o percorsi relativi. Prima tratteremo dei percorsi assoluti.
Un percorso assoluto inizia con la directory root (/) ed è seguita dai rami dell'albero in sequenza, fino al completamento del percorso che porta alla directory o al file desiderati. Per esempio, c'è una directory nel file system in cui sono installati i programmi per il sistema X window. Il percorso è /usr/X11R6/bin. Questo significa che nella directory root (rappresentata dalla barra iniziale nel percorso) c'è una directory chiamata "usr" che contiene una directory chiamata "X11R6", che a sua volta contiene una directory chiamata "bin".
Facciamo una prova:
[io@linuxbox io]$ cd /usr/X11R6/bin
[io@linuxbox io]$ pwd
/usr/X11R6/bin
[io@linuxbox io]$ ls
Animate import xfwp
AnotherLevel lbxproxy xg3
Audio listres xgal
Auto lndir xgammon
Banner makedepend xgc
Cascade makeg xgetfile
Clean mergelib xgopher
Form mkdirhier xhexagons
Ident mkfontdir xhost
Pager mkxauth xieperf
Pager_noxpm mogrify xinit
RunWM montage xiterm
RunWM.AfterStep mtv xjewel
RunWM.Fvwm95 mtvp xkbbell
RunWM.MWM nxterm xkbcomp
e tanti altri file ...
Come si vede, abbiamo cambiato la directory di lavoro corrente alla /usr/X11R6/bin, che è piena di file. Avete notato che il vostro prompt è cambiato? Per comodità, solitamente si imposta il prompt affinché mostri il nome della directory di lavoro.
Mentre un percorso assoluto inizia dalla directory root e conduce alla sua destinazione; un percorso relativo, invece, inizia dalla directory di lavoro. A questo scopo, in un percorso relativo si usa una coppia di simboli speciali per rappresentare le posizioni relative nell'albero del file system. Questi simboli speciali sono: "." (punto) e ".." (punto punto).
Il simbolo "." si riferisce alla directory di lavoro, mentre il simbolo ".." si riferisce alla directory genitrice della directory di lavoro. Di seguito è mostrato come funzionano. Spostiamoci ancora nella directory /usr/X11R6/bin:
[io@linuxbox io]$ cd /usr/X11R6/bin
[io@linuxbox io]$ pwd
/usr/X11R6/bin
Bene, ora supponiamo di voler cambiare la directory di lavoro in quella genitrice della /usr/X11R6/bin, ossia /usr/X11R6. Questo si potrebbe fare in due modi differenti. Il primo usa un percorso assoluto:
[io@linuxbox io]$ cd /usr/X11R6
[io@linuxbox io]$ pwd
/usr/X11R6
Il secondo usa un percorso relativo:
[io@linuxbox io]$ cd ..
[io@linuxbox io]$ pwd
/usr/X11R6
Due metodi differenti con identico risultato. Quale dovreste usare? Quello che richiede la minore digitazione!
Similmente, possiamo cambiare la directory di lavoro da /usr/X11R6 a /usr/X11R6/bin in due modi differenti. Il primo usa un percorso assoluto:
[io@linuxbox io]$ cd /usr/X11R6/bin
[io@linuxbox io]$ pwd
/usr/X11R6/bin
Il secondo usa un percorso relativo:
[io@linuxbox io]$ cd ./bin
[io@linuxbox io]$ pwd
/usr/X11R6/bin
Ora, c'è qualcosa di importante che devo far notare: nella maggioranza dei casi, il "./" è implicito e si può omettere. Se digitate
[io@linuxbox io]$ cd bin
dovreste ottenere lo stesso effetto. In generale, se non si specifica un percorso relativo verso qualcosa, sarà assunta la directory di lavoro. C'è un'eccezione importante a questo comportamento, ma ne parleremo tra poco.
Se digitate cd senza opzioni, cambierete la directory di lavoro nella vostra directory personale in /home.
Una scorciatoia correlata è cd nome_utente. In questo caso, cd cambierà la directory di lavoro alla directory in /home dell'utente specificato.
Ora che sapete come muovervi da una directory di lavoro a un'altra, andremo ad effettuare un giro turistico del sistema Linux ( Lezione 4 - Un Tour Guidato) e, lungo la strada, impareremo alcune cose su come farlo velocemente. Ma prima di iniziare devo insegnarvi l'uso di alcuni strumenti che ci verranno in aiuto durante la nostra avventura. Questi sono:
Il comando ls è utilizzato per elencare i contenuti di una directory; probabilmente è il comando Linux più comunemente utilizzato. Può essere usato in molti modi differenti. Ecco alcuni esempi:
| Comando | Risultato |
| ls | Elenca i file nella directory corrente |
| ls /bin | Elenca i file nella directory /bin (o in qualsiasi directory si voglia specificare) |
| ls -l | Elenca i file nella directory corrente in formato esteso |
| ls -l /etc /bin | Elenca i file nelle directory /bin e /etc in formato esteso |
| ls -la .. |
Elenca tutti i file (anche quelli il cui nome inizia con un punto, che sono normalmente nascosti) nella directory genitrice della directory corrente, in formato esteso. |
Questi esempi indicano anche un importante concetto riguardo ai comandi. La maggior parte dei comandi opera così:
comando -opzioni argomenti
Dove comando è il nome del comando, -opzioni è una o più modifiche del comportamento del comando, e argomenti, una o più "cose" sulle quali il comando opera.
Nel caso di ls, vediamo che ls è il nome del comando che può avere una o più opzioni, come -a e -l, e può operare su uno o più file o directory.
Se usate ls con l'opzione -l otterrete un elenco dei file ricco di informazioni. Ecco un esempio:
-rw------- 1 bshotts bshotts 576 Apr 17 1998 weather.txt
drwxr-xr-x 6 bshotts bshotts 1024 Oct 9 1999 web_page
-rw-rw-r-- 1 bshotts bshotts 276480 Feb 11 20:41 web_site.tar
-rw------- 1 bshotts bshotts 5743 Dec 16 1998 xmas_file.txt
---------- --------- ------- -------- ------------ -------------
| | | | | |
| | | | | Nome del file
| | | | |
| | | | +--- Data/Ora modifica
| | | |
| | | +------------- Dimensione (in byte)
| | |
| | +----------------------- Gruppo
| |
| +-------------------------------- Proprietario
|
+---------------------------------------------- Permessi sui file
Il nome del file o della directory.
L'ultima volta che il file è stato modificato. Se l'ultima modifica è avvenuta più di sei mesi addietro, vengono mostrati la data e l'anno. Altrimenti, è mostrata l'ora del giorno.
La dimensione del file in byte.
Il nome del gruppo per il quale sono specificati i permessi di accesso al file, oltre al proprietario.
Il nome dell'utente a cui appartiene il file.
Una rappresentazione dei permessi di accesso al file. Il primo carattere è il tipo di file. Un "-" indica un file regolare (ordinario). Una "d" indica una directory. Il secondo insieme di tre caratteri rappresenta i diritti di lettura (r), scrittura (w) e esecuzione (x) del proprietario del file. I successivi tre rappresentano i diritti del gruppo del file, e gli ultimi tre rappresentano i diritti accordati a chiunque altro.
less è un programma che permette di visualizzare i file di
testo. È molto utile, dato che molti dei file usati per
controllare e configurare Linux sono leggibili (come non
accade con sistemi operativi proprietari).
Ci sono diversi modi di rappresentare informazioni su un computer. Tutti i metodi comportano la definizione di relazioni tra l'informazione e alcuni numeri che saranno usati per rappresentarla. Dopo tutto i computer comprendono esclusivamente i numeri, e tutti i dati sono convertiti in rappresentazioni numeriche.
Alcuni di questi sistemi di rappresentazione sono molto complessi (come i file di immagini compressi), mentre altri sono piuttosto semplici. Uno dei più vecchi e semplici è chiamato testo ASCII. ASCII (pronunciato "As-Key") è l'abbreviazione di American Standard Code for Information Interchange (codice americano standard per l'interscambio di informazioni), ed è un semplice schema di codifica che venne inizialmente utilizzato sulle macchine telescriventi per stabilire una corrispondenza tra caratteri della tastiera e numeri.
Il testo è una semplice corrispondenza uno-a-uno da caratteri a numeri. È molto compatto. Cinquanta caratteri di testo tradotti in cinquanta byte di dati. In tutto un sistema Linux, molti file sono memorizzati in formato testo e molti strumenti lavorano con file di testo. Anche i sistemi operativi proprietari riconoscono l'importanza di questo formato. Il programma ben conosciuto NOTEPAD.EXE è un editor per file di testo non formattato in codifica ASCII.
Il programma less è richiamato digitando semplicemente:
[io@linuxbox io]$ less file_di_testo
Questo comando mostrerà il contenuto del file.
Una volta avviato, less mostrerà il file di testo una pagina alla volta. Potete usare i tasti Pagina su e Pagina giù per muovervi attraverso il file di testo. Per uscire da less, digitate q.
Ecco alcuni comandi accettati da less:
| Comando | Azione |
| Pagina Su o b | Scorre indietro di una pagina |
| Pagina Giu o spazio | Scorre avanti di una pagina |
| G | Va alla fine del file di testo |
| 1G | Va all'inizio del file di testo |
| /characters | Ricerca in avanti nel file di testo una corrispondenza dei caratteri specificati |
| n | Ripete la ricerca precedente |
| h | Visualizza una lista completa dei comandi e delle opzioni di less |
| q | Quit (Uscita) |
Girovagando nel vostro sistema Linux, prima di aprire un file in lettura sarà utile determinare cosa contiene. Questo è lo scopo del comando file, che esamina un file e dice che tipo di file esso sia.
Per usare il comando file, digitate semplicemente:
[io@linuxbox io]$ file nome_del_file
Il comando file può riconoscere la maggior parte dei tipi di file,
come:
| Tipo di File | Descrizione |
Visualizzabile come testo? |
| ASCII text |
Il nome dice tutto | si |
| Bourne-Again shell script text |
Uno script Bash | si |
| ELF 32-bit LSB core file |
Un file core dump (un programa creerà questo file quando va in crash) | no |
| ELF 32-bit LSB eseguibile |
Un programma binario eseguibile | no |
| ELF 32-bit LSB shared |
Una libreria oggetto condivisa | no |
| GNU tar archive |
Un file archivio tape. Un modo comune di memorizzare gruppi di file | no, usare tar tvf per vedere una lista. |
| gzip compressed data |
Un archivio compresso con gzip | no |
| HTML document text |
Una pagina web | si |
| JPEG image data |
Un'immagine JPEG compressa | no |
| PostScript document text |
Un file PostScript | si |
| RPM |
Un archivio Red Hat Package Manager |
usare rpm -q per esaminare il contenuto. |
| Zip archive data |
Un archivio compresso con zip | no |
Potrebbe sembrare che la maggior parte dei file non possano essere visti come testo; invece i file leggibili in questa forma sono così tanti che ne rimarrete sorpresi. Ciò è particolarmente vero per i file di configurazione importanti. Durante la nostra avventura vi accorgerete che molte caratteristiche del sistema operativo sono controllate da script di shell. In Linux, non ci sono segreti!
È il momento di intraprendere la nostra gita. La tabella seguente fornisce una lista di alcuni luoghi interessanti da esplorare. Questa lista non è esaustiva, ma si dimostrerà un'avventura interessante. Per ognuna delle directory elencate sotto, dare i comandi seguenti:
Di seguito sono elencate alcune delle directory più interessanti e
il loro contenuto:
| Directory | Descrizione |
| / |
La directory root dove inizia il file system. Nella maggior parte dei casi la directory root contiene solo sottodirectory. |
| /boot |
Questa directory è dove sono tenuti il kernel di Linux e il "boot loader". Il kernel è un file chiamato vmlinuz. |
| /etc |
La directory /etc contiene i file di configurazione per il sistema. Tutti i file in /etc dovrebbero essere file di testo. Tra questi file, quelli interessanti sono:
|
| /bin, /usr/bin |
Queste due directory contengono la maggior parte dei programmi per il sistema. La directory /bin contiene i programmi essenziali richiesti dal sistema per funzionare, mentre /usr/bin contiene le applicazioni per gli utenti del sistema. |
| /sbin, /usr/sbin |
Le directory sbin contengono i programmi per l'amministrazione del sistema, in maggior parte usati dal super-utente. |
| /usr |
La directory /usr contiene una varietà di cose che supportano le applicazioni degli utenti. Alcune sottodirectory di rilievo:
|
| /usr/local |
/usr/local e le sue sottodirectory sono usate per l'installazione di software e altri file per l'uso sulla macchina locale. Ciò vuol dire in realtà che il software che non è parte della distribuzione ufficiale (che usualmente \ messo in /usr/bin), viene messo in questa directory. Quando trovate dei programmi interessanti da installare sul vostro sistema, dovrebbero essere installati in una delle directory di /usr/local. Spesso, la directory da scegliere è /usr/local/bin. |
| /var |
La directory /var contiene file che cambiano mentre il sistema è in esecuzione. Questa include:
|
| /lib |
Le librerie condivise (simili alle DLL di quell'altro sistema operativo) sono tenute in questa directory. |
| /home |
/home è la directory in cui gli utenti tengono i loro lavori personali. In generale, questo è l'unico posto dove è dato il permesso di scrittura agli utenti. Ciò rende tutto più ordinato e pulito :-) |
| /root |
Questa è la home directory del super-utente. |
| /tmp |
/tmp è una directory in cui i programmi possono scrivere i loro file temporanei. |
| /dev |
La directory /dev è una directory speciale, in quanto non contiene in realtà file nel senso usuale. Piuttosto, contiene dispositivi disponibili al sistema. In Linux (come in Unix), i dispositivi sono trattati come file. Si può leggere e scrivere sui dispositivi come se fossero dei file. Per esempio /dev/fd0 è il primo lettore dei dischi floppy, /dev/sda (/dev/hda su sistemi più vecchi) è il primo disco fisso. Tutti i dispositivi riconosciuti dal kernel sono rappresentati in questa directory. |
| /proc |
Anche /proc è una directory speciale. Questa directory non contiene file. A dire il vero, la stessa directory non esiste realmente, è interamente virtuale. La directory /proc contiene tanti piccoli spioncini per sbirciare dentro il kernel stesso. In questa directory c'è un gruppo di voci identificate da un numero, che corrispondono a tutti i processi in esecuzione sul sistema. Inoltre, ci sono numerose voci identificate da un nome che permettono l'accesso all'attuale configurazione del sistema. Molte di queste voci possono essere visualizzate. Provate a visualizzare /proc/cpuinfo. Questa voce vi informerà di come il kernel "vede" la propria CPU. |
| /media, /mnt |
Infine, eccoci a /media, una directory normale che è usata in un modo speciale. La directory /media è usata per i punti di mount. Come abbiamo imparato nella lezione 2 ( Navigazione), i differenti dispositivi fisici di memorizzazione (come i dischi fissi) sono innestati all'albero del file system in varie posizioni. Questo processo di innestare un dispositivo all'albero del file system è chiamato montaggio. Affinché un dispositivo sia disponibile, prima deve essere montato.
Quando il sistema si avvia, legge una lista
di istruzioni di montaggio nel file /etc/fstab,
che descrive quale dispositivo è montato
al relativo punto di mount nell'albero delle
directory. Questo riguarda
i dischi fissi, ma si possono avere anche
dispositivi che sono considerati temporanei,
come CD-ROM, thumb drives e floppy disk. Dato che
questi dispositivi sono rimovibili, non rimangono
sempre montati. La directory /media è usata
dai meccanismi di montaggio automatico dei
dispositivi presente nelle moderne distribuzioni
Linux orientate al desktop. Su sistemi che
richiedono un montaggio manuale di dispositivi
rimovibili, la directory /mnt fornisce
un posto conveniente per montare questi
dispositivi temporanei. Spesso vedrete le directory
/mnt/floppy e /mnt/cdrom. Per
vedere quali dispositivi e mount point sono usati,
digitate |
Durante la nostra gita avrete probabilmente notato una strana specie di voci di directory, in particolare nelle directory /boot e /lib. Producendo una lista con il comando ls -l, dovreste vedere qualcosa di simile a questo:
lrwxrwxrwx 25 Jul 3 16:42 System.map -> /boot/System.map-2.0.36-3
-rw-r--r-- 105911 Oct 13 1998 System.map-2.0.36-0.7
-rw-r--r-- 105935 Dec 29 1998 System.map-2.0.36-3
-rw-r--r-- 181986 Dec 11 1999 initrd-2.0.36-0.7.img
-rw-r--r-- 182001 Dec 11 1999 initrd-2.0.36.img
lrwxrwxrwx 26 Jul 3 16:42 module-info -> /boot/module-info-2.0.36-3
-rw-r--r-- 11773 Oct 13 1998 module-info-2.0.36-0.7
-rw-r--r-- 11773 Dec 29 1998 module-info-2.0.36-3
lrwxrwxrwx 16 Dec 11 1999 vmlinuz -> vmlinuz-2.0.36-3
-rw-r--r-- 454325 Oct 13 1998 vmlinuz-2.0.36-0.7
-rw-r--r-- 454434 Dec 29 1998 vmlinuz-2.0.36-3
Notate i file System.map, module-info e vmlinuz. Avete visto la strana notazione dopo il nome dei file?
Questi tre file sono chiamati collegamenti simbolici. I collegamenti simbolici sono uno speciale tipo di file che punta ad un altro file. Con i collegamenti simbolici è possibile avere nomi multipli per un singolo file. Ecco come funziona: ogni volta che al sistema è dato un nome di file che è un collegamento simbolico, esso viene reso corrispondente al file a cui sta puntando.
A che cosa serve? Questa funzionalità è molto utile. Considerate la lista delle directory precedente (che è la directory /boot di un vecchio sistema Red Hat 5.2). Questo sistema ha installate diverse versioni del kernel Linux, e lo si può vedere dai file vmlinuz-2.0.36-0.7 e vmlinuz-2.0.36-3. Questi nomi di file indicano che entrambe le versioni 2.0.36-0.7 e 2.0.36-3 sono installate. Siccome i nomi dei file contengono la versione, è facile vedere le differenze quando si fa la lista dei file nella directory. Tuttavia, questo potrebbe creare confusione ai programmi che dipendono da un nome fisso per il file del kernel. Questi programmi potrebbero aspettarsi che il kernel sia chiamato semplicemente "vmlinuz". Questo è il bello del collegamento simbolico: attraverso la creazione di un collegamento simbolico chiamato vmlinuz, che punta a vmlinuz-2.0.36-3, si risolve il problema.
Per creare collegamenti simbolici, usate il comando
ln.
Questa lezione vi farà conoscere i seguenti comandi:
Questi quattro comandi sono anche tra i comandi di Linux più frequentemente utilizzati. Sono i comandi elementari per gestire file e directory.
Adesso, a essere sinceri, alcuni dei compiti forniti da questi comandi sono ottenibili molto facilmente con un gestore di file grafico, col quale si può trascinare un file da una directory a un'altra, tagliare e incollare file, cancellare file, ecc. Allora, perché usare questi vecchi programmi a riga di comando?
La risposta è: potenza e flessibilità. Mentre è facile realizzare semplici manipolazioni di file con un gestore di file grafico, operazioni più complicate possono essere eseguite più facilmente con programmi a riga di comando. Per esempio, come copiereste tutti i file HTML da una directory a un'altra, però solo i file che non esistono nella directory di destinazione o quelli più recenti delle versioni della directory di destinazione? Piuttosto difficile con un gestore di file. Piuttosto facile con la riga di comando:
[io@linuxbox io]$ cp -u *.html destinazione
Prima di iniziare con i nostri comandi, voglio parlare di una funzionalità della shell che rende questi comandi così potenti. Poiché la shell usa molto i nomi di file, è provvista di caratteri speciali per aiutarvi a specificare rapidamente gruppi di nomi di file. Questi caratteri speciali sono chiamati metacaratteri e permettono di selezionare nomi di file basati su modelli di caratteri.
La tabella sottostante elenca i metacaratteri e cosa selezionano:
| Metacarattere |
Significato |
| * |
Corrisponde ad ogni carattere |
| ? |
corrisponde ad ogni singolo carattere |
| [caratteri] |
Corrisponde a ogni carattere che è uno dei caratteri dell'insieme.
L'insieme dei caratteri può anche essere espresso come una classe di caratteri POSIX come una delle seguenti:
Classi di caratteri POSIX
[:alnum:] Caratteri alfanumerici
[:alpha:] Caratteri alfabetici
[:digit:] Numeri
[:upper:] Caratteri alfanumerici maiuscoli
[:lower:] Caratteri alfanumerici minuscoli
|
| [!caratteri] |
Corrisponde ad ogni carattere che non fa parte dell'insieme di caratteri |
Utilizzando i metacaratteri, è possibile costruire criteri di selezione di nomi di file molto sofisticati.
Di seguito si riportano esempi di modelli e a cosa equivalgono:
| Modello | Corrispondenza |
| * |
Tutti i nomi dei file |
| g* |
Tutti i nomi dei file che iniziano con il carattere "g" |
| b*.txt |
Tutti i nomi dei file che iniziano con il carattere "b" e finiscono con il carattere ".txt" |
| Data??? |
Ogni nome di file che inizia con i caratteri "Data" seguito esattamente tre caratteri |
| [abc]* |
Ogni nome di file che inizia con "a" o "b" o "c" seguito qualsiasi altro carattere |
| [[:upper:]]* |
Ogni nome di file che inizia con una lettera maiuscola. Questo è un esempio di una classe di caratteri. |
| BACKUP.[[:digit:]][[:digit:]] |
Un altro esempio di classe di caratteri. Questo modello corrisponde a ogni nome di file che inizia con i caratteri "BACKUP." seguito esattamente da due numeri. |
| *[![:lower:]] |
Ogni nome di file che non finisce con una lettera minuscola. |
Potete utilizzare i caratteri jolly con qualsiasi comando che accetti nomi di file come argomento.
Il programma cp copia file e directory. Nella sua forma più
semplice, copia un singolo file:
[io@linuxbox io]$ cp file1 file2
Può anche essere utilizzato per copiare più file in una directory differente:
[io@linuxbox io]$ cp file... directory
Una nota sulla notazione: ... significa che una voce può essere ripetuta una o più volte.
Altri utili esempi del comando cp e delle sue opzioni includono:
| Comando | Risultati |
| cp file1 file2 |
Copia il contenuto del file1 dentro il file2. Se il file2 non esiste, viene creato; altrimenti, il file2 è silenziosamente sovrascritto con il contenuto del file1. |
| cp -i file1 file2 |
Come sopra, ma in questo caso, dal momento che è specificata l'opzione "-i" (interattivo), se il file2 esiste l'utente viene avvertito che il file2 sta per essere sovrascritto con il contenuto del file1. |
| cp file1 dir1 |
Copia il contenuto del file1 (dentro un file chiamato file1) all'interno della directory dir1. |
| cp -R dir1 dir2 |
Copia il contenuto della directory dir1. Se la directory dir2 non esiste, viene creata. Altrimenti, crea una directory chiamata dir1 all'interno della directory dir2. |
Il comando mv fornisce due funzioni differenti a seconda di come viene
utilizzato. Esso sposta uno o più file in una directory differente;
oppure rinomina un file o una directory.
Per rinominare un file si usa così:
[io@linuxbox io]$ mv nomefile1 nomefile2
Per spostare file in una directory differente:
[io@linuxbox io]$ mv file1 file2 file3 directory
Esempi di mv e delle sue opzioni includono:
| Comando | Risultati |
| mv file1 file2 |
Se il file2 non esiste, il file1 viene rinominato file2. Se il file2 esiste, il suo contenuto è sostituito silenziosamente con il contenuto del file1. |
| mv -i file1 file2 |
Come il precedente, ma in questo caso, dato che è specificata l'opzione "-i" (interattivo), se il file2 esiste l'utente viene avvertito prima che esso sia sovrascritto con il contenuto del file1. |
| mv file1 file2 file3 dir1 |
I file file1, file2,
file3 sono spostati alla directory
dir1. Se dir1 non esiste,
|
| mv dir1 dir2 |
Se dir2 non esiste, allora dir1 è rinominata dir2. Se dir2 esiste, la directory dir1 è spostata all'interno della directory dir2. |
Il comando rm rimuove (cancella) file e directory.
[io@linuxbox io]$ rm file...
Può anche essere utilizzato per cancellare directory:
[io@linuxbox io]$ rm -r directory...
Esempi di rm e delle sue opzioni includono:
| Comando | Risultati |
| rm file1 file2 |
Cancella file1 e file2. |
| rm -i file1 file2 |
Come il precedent, ma in questo caso, dato che l'opzione "-i" (interattivo) è specificata, l'utente viene avvertito prima che ogni file sia cancellato. |
| rm -r dir1 dir2 | Le directory dir1 e dir2vengono cancellate insieme a tutto il lorocontenuto. |
|
Fate attenzione quando usate rm! |
|
Linux non possiede un comando "undelete" (annulla la cancellazione).
Una volta che si cancella qualcosa con
Prima di usare |
Il comando mkdir è utilizzato per creare le directory. Per
usarlo, digitate semplicemente:
[io@linuxbox io]$ mkdir dir
Dato che i comandi che abbiamo spiegato qui accettano nomi di file multipli e directory come argomenti, potete usare i metacaratteri per specificarli. Qui ci sono un po' di esempi:
| Comando |
Risultati |
| cp *.txt file testo |
Copia tutti i file nella directory di lavoro corrente con i nomi che finiscono con i caratteri ".txt" in una directory esistente chiamata file_testo. |
| mv mia dir ../*.bak mia nuova dir |
Sposta la sottodirectory mia_dir e tutti i file che terminano in ".bak" della directory genitrice della directory di lavoro corrente in una directory esistente chiamata mia_nuova_dir. |
| rm *~ |
Cancella tutti i file nella directory di lavoro corrente che terminano con il carattere "~". Alcune applicazioni creano file di backup usando questo schema nel nome. Usando questo comando si elimineranno da una directory. |
Fino ad ora avete visto svariati comandi e i loro misteriosi argomenti e opzioni. In questa lezione, proveremo a dissipare alcuni di questi misteri. Questa lezione introdurrà i seguenti comandi.
I comandi possono essere di uno di questi 4 tipi differenti:
cd è un comando
incorporato della shell.Spesso è utile sapere esattamente quale dei 4 tipi di comandi si sta usando e Linux fornisce un paio di modi per scoprirlo.
Il comando type è un comando incorporato della shell che mostra il tipo
di comando che la shell eseguirà, dato un determinato nome di comando.
Funziona in questo modo:
type comando
dove "comando" è il nome del comando che si vuole esaminare. Qui ci sono alcuni esempi:
[io@linuxbox io]$ type type
type è un comando interno di shell
[io@linuxbox io]$ type ls
ls ha `ls --color=tty` come alias
[io@linuxbox io]$ type cp
cp è /bin/cp
Qui vediamo il risultato di tre comandi differenti. Notare quello per ls (preso da un sistema Fedora) e come il comando ls sia in effetti un alias per il comando ls con l'opzione "-- color=tty" aggiunta. Ora sappiamo il perché l'output di ls è mostrato a colori!
Qualche volta c'è più di una versione di un programma eseguibile
intallata su di un sistema. Mentre questo non è molto comune su sistemi
desktop, non è inusuale su grandi server. Per determinare l'esatta posizione
di un dato eseguibile, si usa il comando which:
[io@linuxbox io]$ which ls
/bin/ls
Il comando which funziona solo per programmi eseguibili, non per
i comandi incorporati né per alias che sono sostituti di programmi
eseguibili effettivi.
Con queste nozioni su cosa è un comando, ora possiamo cercare la documentazione disponibile per ogni genere di comando.
bash ha una funzione di aiuto in linea disponibile per ogni comando
incorporato della shell. Per usarla, digitare "help" seguito dal nome del
comando incorporato della shell. Opzionalmente, si può aggiungere
l'opzione -m per cambiare il formato di uscita. Per esempio:
[io@linuxbox io]$ help -m cd
NAME
cd - Change the shell working directory.
SYNOPSIS
cd [-L|-P] [dir]
DESCRIPTION
Change the shell working directory.
Change the current directory to DIR. The default DIR is the value of the
HOME shell variable.
The variable CDPATH defines the search path for the directory containing
DIR. Alternative directory names in CDPATH are separated by a colon (:).
A null directory name is the same as the current directory. If DIR begins
with a slash (/), then CDPATH is not used.
If the directory is not found, and the shell option `cdable_vars' is set,
the word is assumed to be a variable name. If that variable has a value,
its value is used for DIR.
Options:
-L force symbolic links to be followed
-P use the physical directory structure without following symbolic
links
The default is to follow symbolic links, as if `-L' were specified.
Exit Status:
Returns 0 if the directory is changed; non-zero otherwise.
SEE ALSO
bash(1)
IMPLEMENTATION
GNU bash, version 4.1.5(1)-release (i486-pc-linux-gnu)
Copyright (C) 2009 Free Software Foundation, Inc.
Un nota sulla notazione: Quando le parentesi quadre appaiono nella
descrizione della sintassi di un comando, indicano elementi opzionali. Un carattere
di barra verticale indica elementi mutualmente esclusivi. Nel caso del comando
cd visto sopra:
cd [-L|-P] [dir]
Questa notazione dice che il comando cd può essere seguito,
opzionalmente, o da un'opzione "-L" o da una "-P", e può anche essere
seguito opzionalmente dall'argomento "dir".
Molti programmi eseguibili supportano una opzione "--help" che mostra una descrizione della sintassi del comando supportata e le opzioni. Per esempio:
[io@linuxbox io]$ mkdir --help
Uso: mkdir [OPZIONE]... DIRECTORY...
Crea la/le DIRECTORY, se ancora non esiste.
-Z, --context=CONTEXT (SELinux) imposta il contesto di sicurezza a CONTEXT
Gli argomenti obbligatori per le opzioni lunghe valgono anche per quelle brevi.
-m, --mode=MODO imposta i permessi (come in chmod), non a=rwx - umask
-p, --parents nessun errore se esiste, crea la directory genitrice se
necessario
-v, --verbose stampa un messaggio per ogni directory creata
--help mostra questo aiuto ed esce
--version stampa le informazioni sulla versione ed esce
Alcuni programmi non supportano l'opzione "--help", ma si può comunque provare. Spesso termina con un messaggio di errore che mostra un'informazione simile sull'uso del comando.
La maggior parte dei programmi eseguibili destinati per l'uso dalla riga di comando
forniscono una parte di documentazione formale chiamata manuale o man page.
Uno speciale programma di paginazione chiamato man è usato per vedere questa
documentazione. Questo programma è usato nel modo seguente:
man programma
ls:
[io@linuxbox io]$ man ls
Sulla maggior parte dei sistemi Linux, man usa less per visualizzare
la pagina di manuale, così tutti i comandi familiari di less funzionano
mentre si stà visualizzando la pagina.
Molti dei pacchetti di software installati nel sistema hanno i file di
documentazione che si trovano nella directory /usr/share/doc. La maggior parte
di questi file sono memorizzati in formato di testo piano (semplice) e possono
essere visualizzati con il browser web. Si possono incontrare alcuni file
che terminano con l'estensione ".gz". Questo indica che sono stati compressi con
il programma di compressione gzip. Il pacchetto gzip include una versione
speciale di less chiamata zless che visualizzerà il contenuto dei file di
testo compressi con gzip.
In questa lezione esploreremo una potente funzionalità, usata da molti
programmi a riga di comando, chiamata redirezione input/output.
Come abbiamo visto, molti comandi come ls stampano il risultato sullo schermo.
Tuttavia, questo non deve essere l'unico comportamento. Attraverso l'uso
di alcune notazioni speciali possiamo ridirigere l'uscita di molti
comandi verso file, dispositivi e anche verso l'input di altri comandi.
La maggior parte dei programmi a riga di comando che mandano a video i loro risultati, lo fanno inviandoli verso una funzionalità chiamata standard output. Come comportamento predefinito, lo standard output dirige il suo contenuto verso lo schermo; per ridirigere lo standard output verso un file, si usa il carattere ">" nel seguente modo:
[io@linuxbox io]$ ls > lista_file.txt
In questo esempio, viene eseguito il comando ls e il risultato
è scritto in un file chiamato lista_file.txt. Poich l'uscita di
ls è stata ridiretta al file, non appare alcun risultato
sullo schermo.
Ogni volta che il comando precedente viene ripetuto, il file lista_file.txt
viene ricreato con l'output del comando ls. Se invece si vuole che il
nuovo risultato sia accodato alla fine del file, si deve usare ">>" nel
seguente modo:
[io@linuxbox io]$ ls >> lista_file.txt
Quando il risultato è accodato, il nuovo risultato è aggiunto alla fine del file, rendendo così il file sempre più grande ad ogni ripetizione del comando. Se il file non esiste, verrà creato.
Molti comandi possono accettare l'input da una funzionalità chiamata standard input. Come comportamento predefinito, lo standard input ottiene i suoi contenuti dalla tastiera ma, come per lo standard output, può essere ridiretto. Per ridirigere lo standard input da un file invece che dalla tastiera, si usa il carattere "<" nel seguente modo:
[io@linuxbox io]$ sort < lista_file.txt
Nell'esempio precedente, per elaborare il contenuto del file lista_file.txt è stato usato il comando sort. Il risultato è stampato sullo schermo, perché in quest'esempio lo standard output non viene ridiretto. Potremmo ridirigere lo standard output ad un altro file in questo modo:
[io@linuxbox io]$ sort < lista_file.txt > lista_file_ordinata.txt
Come potete vedere, un comando può aver rediretti sia il proprio input, sia il proprio output. Tenete presente che l'ordine della redirezione non è importante. L'unico requisito è che gli operatori di redirezione (i caratteri "<" e ">") appaiano dopo le altre opzioni e gli argomenti del comando.
La cosa più utile ed efficace da fare con la redirezione I/O, è la connessione di più comandi attraverso le cosiddette pipeline. Con le pipeline, lo standard output di un comando vien fatto confluire nello standard input di un altro. Questo esempio è il mio preferito in assoluto:
[io@linuxbox io]$ ls -l | less
In questo esempio, l'output del comando ls è convogliato nel
comando less. Con l'uso del trucco "| less" potete permettere
all'utente di scorrere liberamente l'output di qualsiasi comando.
È una tecnica che uso sempre.
Attraverso la connessione di più comandi, si possono compiere imprese sorprendenti. Di seguito ci sono alcuni esempi che potrete provare:
| Comando |
Che cosa fa |
| ls -lt | head |
Visualizza i 10 file più recenti nella directory corrente. |
| du | sort -nr |
Visualizza una lista di directory e quanto spazio consumano, ordinati dalla più grande alla più piccola. |
| find . -type f -print | wc -l |
Visualizza il numero totale di file nella directory di lavoro corrente e in tutte le sue sottodirectory. |
Un tipo di programma usato frequentemente usato nelle pipeline è chiamato filtri. I filtri ricevono lo standard input, effettuano un'operazione su di esso e inviano i risultati allo standard output. Possono essere combinati tra di loro per elaborare efficacemente le informazioni. Questi sono alcuni dei programmi più comuni che possono agire come filtri:
| Programma |
Che cosa fa |
| sort |
Riceve lo standard input e lo invia ordinato allo standard output. |
| uniq |
Dato un flusso ordinato di dati dallo standard input, elimina le righe duplicate (assicura, cioè, che ogni riga sia univoca). |
| grep |
Esamina tutte le righe di dati che riceve dallo standard input ed emette solo quelle che contengono una combinazione di caratteri specificata |
| fmt |
Legge testo dallo standard input e lo emette formattato sullo standard output. |
| pr |
Prende testo dallo standard input e lo prepara per la stampa inserendo interruzioni di pagina, intestazioni e note a piè di pagina. |
| head |
Emette le prime (poche) righe ricevute dallo standard input. Utile per ottenere l'intestazione di un file. |
| tail |
Emette le ultime (poche) righe ricevute dallo standard input. Utile, ad esempio, per ottenere gli ultimi inserimenti in un file di log. |
| tr |
Traduce caratteri. Può essere usato per esegure compiti come la conversione maiuscolo/minuscolo o cambiare i caratteri di fine riga da un tipo all'altro (per esempio, la conversione di file di testo DOS in file di testo in stile Unix). |
| sed |
Editor di flusso. Può effettuare trasformazioni
di testo più sofisticate rispetto a |
| awk |
Un intero linguaggio di programmazione progettato per la costruzione di filtri. Estremamente potente. |
lpr che riceve lo
standard input e lo invia alla stampante. È usato
spesso con le pipeline e i filtri. Ecco un paio di esempi:
cat report_formattato_male.txt | fmt | pr | lpr
cat lista_non_ordinata_con_duplicati.txt | sort | uniq | pr | lpr
Nel primo esempio, usiamo cat per leggere il file e
immetterlo sullo standard output, che è convogliato
nello standard input del comando fmt. fmt
formatta il testo dentro paragrafi stabiliti e lo emette sul suo
standard output, che è convogliato nello standard input
di pr. pr divide il testo ordinato in pagine e
lo emette sullo standard output, che è inviato dentro lo
standard input di lpr. lpr prende il suo standard
input e lo invia alla stampante.
Il secondo esempio inizia con un lista di dati non ordinata con
linee duplicate. All'inizio, cat invia la lista dentro
sort, che la ordina e la invia dentro uniq;
quest'ultimo rimuove ogni riga duplicata. In seguito, pr e
lpr sono rispettivamente usati per impaginare e stampare
la lista.
tar
e compressi con il comando
gzip, che
tradizionalmente vengono salvati
nelle unità a nastro gestite dai sistemi Unix. Questi file
si possono identificare attraverso le loro tradizionali estensioni:
".tar.gz" o ".tgz". Per vedere il contenuto di questi file su un
sistema Linux, si può usare il comando:
tar tzvf nome_del_file.tar.gz | less
Ogni volta che si scrive su una riga di comando e si preme il tasto invio,
bash esegue diverse elaborazioni sul testo prima di eseguire il
comando. Abbiamo visto in un paio di casi come una sequenza di un solo
carattere, per esempio "*", può avere diversi significati per la shell.
Il processo che permette che questo succeda è chiamato espansione. Con
l'espansione, si digita qualcosa che si espande in qualcos'altro prima che la
shell agisca su di esso. Per dimostrare cosa si intende con questo, andiamo a
dare uno sguardo al comando echo. Il comando echo è un
comando incorporato della shell che esegue un compito molto semplice. Stampa i
suoi argomenti di testo sullo standard output:
[io@linuxbox io]$ echo questo � un test
questo � un test
Questo è abbastanza semplice. Qualsiasi argomento passato al comando
echo viene visualizzato. Proviamo un altro esempio:
[io@linuxbox io]$ echo *
Desktop Documents ls-output.txt Music Pictures Public Templates Videos
Allora cosa è appena successo? Perché il comando echo
non ha stampato il carattere "*"? Come ci si ricorderà dal nostro lavoro
con "caratteri jolly", il carattere "*" significa trovare qualsiasi
carattere in un nome di file, ma quello che non abbiamo visto nella nostra
discussione originale è come la shell riesce a fare questo. La risposta
più semplice è che la shell espande il "*" in qualcos'altro (in
questo caso, i nomi dei file nella directory di lavoro corrente) prima che il
comando echo sia eseguito. Quando si preme il tasto Invio, la shell
espande automaticamente ogni carattere qualificato sulla riga di comando prima
che il comando venga eseguito, quindi il comando echo non ha mai visto
il "*", solo il suo risultato espanso. Sapendo questo, possiamo vedere che il
comando echo si comporta come previsto.
Il meccanismo con cui i caratteri jolly funzionano si chiama espansione del percorso. Se proviamo alcune delle tecniche che abbiamo impiegato nelle nostre precedenti lezioni, vedremo che esse sono davvero espansioni. Data una directory di home che assomiglia a questo:
[io@linuxbox io]$ ls
Desktop
ls-output.txt
Documents Music
Pictures
Public
Templates
Videos
potremmo effettuare le seguenti espansioni:
[io@linuxbox io]$ echo D*
Desktop Documents
e:
[io@linuxbox io]$ echo *s
Documents Pictures Templates Videos
o anche:
[io@linuxbox io]$ echo [[:upper:]]*
Desktop Documents Music Pictures Public Templates Videos
e, guardando oltre la nostra directory di home:
[io@linuxbox io]$ echo /usr/*/share
/usr/kerberos/share /usr/local/share
Come ricorderete dalla nostra introduzione al comando cd, il carattere
tilde (~) ha uno speciale significato. Quando viene utilizzato all'inizio di
una parola, si espande nel nome della directory di home dell'utente indicato o,
se non viene indicato nessun utente, la directory di home dell'utente corrente:
[io@linuxbox io]$ echo ~
/home/io
Se l'utente "pippo" ha un account:
[io@linuxbox io]$ echo ~pippo
/home/pippo
La shell permette di eseguire calcoli mediante espansione. Questo ci permette di utilizzare il prompt della shell come una calcolatrice:
[io@linuxbox io]$ echo $((2 + 2))
4
l'espansione aritmetica usa la forma:
$((espressione))
dove l'espressione è un'espressione aritmetica che consiste di valori e di operatori aritmetici.
L'espansione aritmetica può supportare solo numeri interi (numeri interi, non decimali), ma può realizzare un certo numero di operazioni differenti.
Gli spazi non sono significativi in espressioni aritmetiche e le espressioni possono essere nidificate. Ad esempio, per moltiplicare cinque al quadrato per tre:
[io@linuxbox io]$ echo $(($((5**2)) * 3))
75
Parentesi singole possono essere utilizzate per raggruppare più sottoespressioni. Con questa tecnica, possiamo riscrivere l'esempio precedente e ottenere lo stesso risultato usando un'unica espansione invece di due:
[io@linuxbox io]$ echo $(((5**2) * 3))
75
Ecco un esempio che utilizza gli operatori di divisione e di resto. Si noti l'effetto di divisione intera:
[io@linuxbox io]$ echo Cinque diviso due � uguale a $((5/2))
Cinque diviso due � uguale a 2
[io@linuxbox io]$ echo col resto di $((5%2)).
col resto di 1.
Forse l'espansione più strana è chiamata espansione delle parentesi graffe. Con essa, è possibile creare più stringhe di testo da un modello contenente le parentesi graffe. Ecco un esempio:
[io@linuxbox io]$ echo Front-{A,B,C}-Back
Front-A-Back Front-B-Back Front-C-Back
I modelli che usano l'espansione delle parentesi graffe possono contenere una porzione iniziale chiamata preambolo e una porzione terminale chiamata appendice. La stessa espressione tra parentesi può contenere un elenco di stringhe separate da virgole, o un intervallo di numeri interi o di caratteri singoli. Il modello non può contenere spazi bianchi incorporati. Ecco un esempio utilizzando un intervallo di numeri interi:
[io@linuxbox io]$ echo Numero_{1..5}
Numero_1 Numero_2 Numero_3 Numero_4 Numero_5
Un intervallo di lettere in ordine inverso:
[io@linuxbox io]$ echo {Z..A}
Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
Le espressioni tra parentesi graffe possono essere annidate:
[io@linuxbox io]$ echo a{A{1,2},B{3,4}}b
aA1b aA2b aB3b aB4b
Quindi, per cosa va bene questo? L'applicazione più comune è quella di creare elenchi di file o directory. Ad esempio, se si fosse un fotografo e si avesse una grande collezione di immagini e si volesse organizzarla in anni e mesi, la prima cosa che si potrebbe fare è creare una serie di directory chiamate in formato numerico "Anno-Mese". In questo modo, i nomi delle directory sarebbero ordinate in ordine cronologico. Si potrebbe digitare un elenco completo di directory, ma questo sarebbe una gran quantità di lavoro e sarebbe soggetto a troppi errori. Invece, si potrebbe fare questo:
[io@linuxbox io]$ mkdir Foto
[io@linuxbox io]$ cd Foto
[io@linuxbox Photos]$ mkdir {2007..2009}-0{1..9} {2007..2009}-{10..12}
[io@linuxbox Photos]$ ls
2007-01 2007-07 2008-01 2008-07 2009-01 2009-07
2007-02 2007-08 2008-02 2008-08 2009-02 2009-08
2007-03 2007-09 2008-03 2008-09 2009-03 2009-09
2007-04 2007-10 2008-04 2008-10 2009-04 2009-10
2007-05 2007-11 2008-05 2008-11 2009-05 2009-11
2007-06 2007-12 2008-06 2008-12 2009-06 2009-12
Piuttosto efficiente!
In questa lezione accenneremo brevemente all'espansione di parametro, che verrà affrontato più compiutamente in seguito. È una funzionalità che è più utile negli script di shell che direttamente sulla riga di comando. Molte delle sue proprietà hanno a che fare con la capacità del sistema di immagazzinare piccole porzioni di dati e di dare ad ogni porzione un nome. Molti di questi "pezzi", più propriamente detti variabili, sono disponibili per essere esaminate. Per esempio, la variabile denominata "USER" contiene il proprio nome utente. Per richiamare l'espansione di parametro e rivelare il contenuto di USER si dovrebbe fare questo:
[io@linuxbox io]$ echo $USER
io
Per vedere una lista di variabili disponibili, provare questo:
[io@linuxbox io]$ printenv | less
Avrete notato che con altri tipi di espansione, se si digita in modo errato un modello, l'espansione non avrà luogo e il comando echo semplicemente visualizzerà il modello digitato in modo errato. Con l'espansione di parametro, se si sbaglia a scrivere il nome di una variabile, l'espansione avrà comunque luogo, ma si tradurrà in una stringa vuota:
[io@linuxbox io]$ echo $SUER
[io@linuxbox ~]$
La sostituzione di comando ci permette di utilizzare l'uscita di un comando come un'espansione:
[io@linuxbox io]$ echo $(ls)
Desktop Documents ls-output.txt Music Pictures Public Templates Videos
Uno dei miei preferiti è qualcosa di simile a questo:
[io@linuxbox io]$ ls -l $(which cp)
-rwxr-xr-x 1 root root 71516 2007-12-05 08:58 /bin/cp
Qui abbiamo passato il risultato di which cp come argomento al
comando ls, ottenendo in tal modo l'elenco del programma cp,
senza dover conoscere il suo percorso completo. Ma non ci limitiamo solo ai
comandi semplici. Possono essere usate intere pipeline (è mostrato
solo un output parziale):
[io@linuxbox io]$ file $(ls /usr/bin/* | grep bin/zip)
/usr/bin/bunzip2:
/usr/bin/zip: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.15, stripped
/usr/bin/zipcloak: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.15, stripped
/usr/bin/zipgrep: POSIX shell script text executable
/usr/bin/zipinfo: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.15, stripped
/usr/bin/zipnote: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.15, stripped
/usr/bin/zipsplit: ELF 32-bit LSB executable, Intel 80386, version 1
(SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.15, stripped
In questo esempio, il risultato della pipeline diventa la lista degli argomenti del comando file. Vi è una sintassi alternativa per la sostituzione dei comandi nei programmi di shell meno recenti, che è supportata anche in bash. Essa usa gli apici inversi al posto del simbolo del dollaro e le parentesi:
[io@linuxbox io]$ ls -l `which cp`
-rwxr-xr-x 1 root root 71516 2007-12-05 08:58 /bin/cp
Ora che abbiamo visto in quanti modi la shell è in grado di eseguire espansioni, è il momento di imparare come possiamo controllarli. Prendiamo ad esempio:
[io@linuxbox io]$ echo questa è una prova
questa è una prova
o:
[io@linuxbox io]$ [io@linuxbox ~]$ echo Il tolale è $100.00
Il tolale è 00.00
Nel primo esempio, la suddivisione in parole dalla shell ha rimosso gli spazi in più dalla lista di argomenti del comando echo. Nel secondo esempio, l'espansione di parametro ha sostituito una stringa vuota per il valore di "$1" perch era una variabile non definita. La shell fornisce un meccanismo chiamato quoting per sopprimere in modo selettivo le espansioni indesiderate.
Il primo tipo di quoting che vedremo è a doppi apici. Se si inserisce del testo all'interno di apici doppi, tutti i caratteri speciali usati dalla shell perdono il loro significato speciale e sono trattati come caratteri ordinari. Le eccezioni sono "$", "\" (barra rovesciata), e "` " (apice inverso). Ciò significa che la suddivisione in parole, l'espansione del percorso, l'espansione della tilde, e l'espansione delle parentesi graffe vengono soppresse, ma l'espansione di parametro, l'espansione aritmetica e la sostituzione di comando sono ancora svolte. Usando gli apici doppi, siamo in grado di far fronte ai nomi di file contenenti spazi incorporati. Mettiamo che siete stati la sfortunata vittima di un file chiamato due parole.txt. Se provaste a usarlo sulla riga di comando, la suddivisione in parole farebbe sì che questo file venga trattato come due argomenti distinti, piuttosto che come un unico argomento:
[io@linuxbox io]$ ls -l due parole.txt
ls: impossibile accedere a due: File o directory non esistente
ls: impossibile accedere a parole.txt: File o directory non esistente
Usando i doppi apici, si può fermare la suddivisione in parole e ottenere il risultato desiderato; inoltre, si possono anche riparare i danni:
[io@linuxbox io]$ ls -l "due parole.txt"
-rw-rw-r-- 1 io io 18 2008-02-20 13:03 due parole.txt
[io@linuxbox io]$ mv "due parole.txt" due_parole.txt
Fatto! Ora non si devono più inserire quei fastidiosi doppi apici. Ricordare, espansione di parametro, espansione aritmetica, e la sostituzione di comando avvengono ancora tra doppi apici:
[io@linuxbox io]$ echo "$USER $((2+2)) $(cal)"
io 4
February 2008
Su Mo Tu We Th Fr Sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29
Dovremmo fermarci un momento per osservare l'effetto dei doppi apici sulla sostituzione di comando. Prima diamo un'occhiata un po' più a fondo su come funziona la suddivisione in parole. Nel nostro esempio precedente, abbiamo visto come la suddivisione in parole sembra rimuovere gli spazi aggiuntivi nel nostro testo:
[io@linuxbox io]$ echo questa è una prova
questa è una prova
Per impostazione predefinita, la suddivisione in parole cerca la presenza di spazi, tabulazioni e ritorni a capo (caratteri di avanzamento riga) e li tratta come delimitatori tra le parole. Ciò significa che spazi, tabulazioni e ritorni a capo che non sono tra virgolette non sono considerati parte del testo. Servono solo come separatori. Dal momento che separano le parole in diversi argomenti, la nostra riga di comando di esempio contiene un comando seguito da quattro distinti argomenti. Se aggiungiamo dei doppi apici:
[io@linuxbox io]$ echo "this is a test"
this is a test
la suddivisione in parole è soppressa e gli spazi incorporati non sono trattati come delimitatori, anzi diventano parte dell'argomento. Una volta aggiunti i doppi apici, la nostra riga di comando contiene un comando seguito da un argomento unico. Il fatto che i ritorni a capo sono considerati delimitatori dal meccanismo di suddivisione in parole provoca un interessante, seppur tenue, effetto sulla sostituzione di comando. Si consideri il seguente:
[io@linuxbox io]$ echo $(cal)
February 2008 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
19 20 21 22 23 24 25 26 27 28 29
[io@linuxbox io]$ echo "$(cal)"
February 2008
Su Mo Tu We Th Fr Sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29
Nel primo caso, la sostituzione di comando senza doppi apici ha dato luogo a una riga di comando che contiene trentotto argomenti. Nel secondo, una riga di comando con un argomento che include gli spazi incorporati e i ritorni a capo.
Se c'è la necessità di sopprimere tutte le espansioni, si usano gli apici singoli. Di seguito un confronto tra un testo senza apici, con doppi apici e con apici singoli:
[io@linuxbox io]$ echo text ~/*.txt {a,b} $(echo pippo) $((2+2)) $USER
text /home/io/ls-output.txt a b pippo 4 io
[io@linuxbox io]$ echo "text ~/*.txt {a,b} $(echo pippo) $((2+2)) $USER"
text ~/*.txt {a,b} pippo 4 io
[io@linuxbox io]$ echo 'text ~/*.txt {a,b} $(echo pippo) $((2+2)) $USER'
text ~/*.txt {a,b} $(echo pippo) $((2+2)) $USER
Come si può vedere, a ogni livello successivo di quoting vengono soppresse sempre più espansioni.
A volte si desidera solo mettere tra apici un solo carattere. Per far questo, è possibile far precedere un carattere da una barra rovesciata, che in questo contesto si chiama il carattere di escape. Spesso questo viene fatto all'interno di doppi apici per impedire selettivamente un'espansione:
[io@linuxbox io]$ echo "Il saldo per l'utente $USER �: \$5.00"
Il saldo per l'utente io �: $5.00
È comune anche l'uso di caratteri di escape per eliminare il significato speciale di un carattere in un nome di file. Per esempio, è possibile usare nei nomi di file caratteri che normalmente hanno un significato speciale per la shell. Questi dovrebbero includere "$", "!", "&", "", e altri. Per includere un carattere speciale in un nome di file è possibile fare questo:
[io@linuxbox io]$ mv bad\&filename good_filename
Per consentire a un carattere di barra rovesciata di apparire, proteggerla digitando "\\". Si noti che all'interno di apici singoli, la barra rovesciata perde il suo significato speciale ed è trattata come un carattere normale.
Se si consultano le pagine man per ogni programma scritto dal progetto
GNU, si noterà che, oltre a opzioni della riga di comando costituite da
un trattino e una sola lettera, ci sono anche nomi di opzioni lunghi che
iniziano con due trattini. Ad esempio, i seguenti comandi sono equivalenti:
ls -r
ls --reverse
Perché sono possibili entrambe le forme? La forma breve è per i dattilografi pigri sulla riga di comando e la forma lunga è usata principalmente per gli script anche se alcune opzioni potrebbero essere solo in forma lunga. A volte uso le opzioni oscure, e trovo utile la forma lunga se devo rivedere ancora uno script mesi dopo averlo scritto. Vedendo la forma lunga mi aiuta a capire che cosa fa l'opzione, mi risparmio un viaggio alla pagina man. Ora un po' più di battitura, più tardi molto meno lavoro. La pigrizia viene mantenuta.
Come si potrebbe sospettare, usando le opzioni in forma lunga si può ottenere un'unica riga di comando molto lunga. Per risolvere questo problema, è possibile usare una barra rovesciata affinché la shell ignori un carattere di ritorno a capo, come di seguito:
ls -l \
--reverse \
--human-readable \
--full-time
Utilizzando la barra rovesciata in questo modo ci permette di includere dei ritorno a capo nel nostro comando. Si noti che affinché questo trucco funzioni, il ritorno a capo dev'essere digitato immediatamente dopo la barra rovesciata. Se si mette uno spazio dopo la barra rovesciata, lo spazio verrà ignorato, non il ritorno a capo. Le barre rovesciate sono usate anche per inserire caratteri speciali dentro il nostro testo. Questi sono chiamati sequenze di escape. Ecco i più comuni:
| Sequenza di escape | Nome |
Usi Possibili |
| \n | a capo |
Aggiunge righe vuote al testo |
| \t | tabulazione |
Inserisce tabulazioni orizzontali al testo |
| \a | avviso |
Produce beep al proprio terminale |
| \\ | barra rovesciata |
Inserisce una barra rovesciata |
| \f | salto pagina |
Inviandolo alla stampante termina la pagina |
L'uso della barra rovesciata come carattere di protezione è molto
comune. Questa idea apparve per la prima volta nel linguaggio di programmazione
C. Oggi, la shell, C++, perl, python, awk, tcl e molti altri linguaggi di
programmazione usano questo concetto. L'uso del comando echo con
l'opzione -e ci permetterà di mostrare l'uso della barra rovesciata:
[io@linuxbox io]$ echo -e "Inserire diverse righe vuote\n\n\n"
Inserire diverse righe vuote
[io@linuxbox io]$ echo -e "Parole\tseparate\tda\ttabulazioni\ttorizzontali."
Parole separate da tabulazioni orizzontali
[io@linuxbox io]$ echo -e "\aIl mio computer faceva \"beep\"."
Il mio computer faceva "beep".
[io@linuxbox io]$ echo -e "DEL C:\\WIN2K\\LEGACY_OS.EXE"
DEL C:\WIN2K\LEGACY_OS.EXE
I sistemi operativi derivati da Unix, come Linux, differiscono da altri sistemi per computer per il fatto di non essere soltanto multitasking, ma anche multiutente.
Cosa significa esattamente? Significa che più utenti possono usare il computer nello stesso momento. Benché il proprio computer abbia una sola tastiera e un solo monitor, esso può essere usato anche da più di un utente. Per esempio, se il vostro computer è collegato a una rete o a internet, utenti remoti possono eseguire l'accesso attraverso telnet o ssh (la secure shell) e operare sul computer. Di fatto, utenti remoti possono eseguire applicazioni X e visualizzarne l'output grafico su un computer remoto. Il sistema X Window prevede questa funzionalità.
La capacità multiutente dei sistemi tipo Unix non è una "innovazione" recente ma piuttosto una caratteristica che è profondamente radicata nel progetto del sistema operativo. Se ricordate l'ambiente nel quale Unix venne creato ciò acquista senso compiuto. Anni prima che divenissero "personali", i computer erano grandi, costosi e centralizzati. Un tipico sistema di computer universitario consisteva di un grande elaboratore principale collocato in un palazzo del campus, e i terminali erano disseminati in tutto il campus, ciascuno connesso al grande computer centrale. Il computer doveva consentire l'accesso a molti utenti allo stesso momento.
Al fine di rendere fattibile tutto ciò, fu escogitato un metodo per proteggere un generico utente dagli altri. Dopo tutto, se non si voleva permettere a un utente di mandare in crash il computer, non si voleva nemmeno che un utente potesse interferire coi file appartenenti ad un altro utente.
Questa lezione affronterà i seguenti comandi:
Su un sistema Linux, a ciascun file e directory sono assegnati diritti di accesso per il proprietario del file, per i membri di un gruppo di utenti correlati e per tutti gli altri utenti del sistema. Possono essere assegnati i diritti di lettura, scrittura ed esecuzione di un file (per esempio, l'avvio di un file come programma).
Per vedere le impostazioni dei permessi per un file, possiamo
usare il comando ls. Come esempio, vedremo il programma bash,
che si trova nella directory /bin:
[io@linuxbox io]$ ls -l /bin/bash
-rwxr-xr-x 1 root root 316848 Feb 27 2000 /bin/bash
Qui possiamo vedere che:
Nel diagramma sottostante, vediamo come viene interpretata la prima porzione del listato. Essa consiste di un carattere che indica il tipo di file, seguito da tre insiemi di tre caratteri che racchiudono i permessi di lettura, scrittura ed esecuzione per il proprietario, per il gruppo e per tutti gli altri.
- rwx rw- r--
___ ___ ___
^ ^ ^ ^
| | | |__________ Permessi di lettura (r), scrittura (w) ed
| | | esecuzione (x) per tutti gli altri utenti.
| | |
| | |______________ Permessi di lettura (r), scrittura (w) ed
| | esecuzione (x) per i membri appartenenti al
| | gruppo del file.
| |
| |__________________ Permessi di lettura (r), scrittura (w) ed
| esecuzione (x) per il proprietario del file.
|
|_____________________ Tipo di file. Il trattino "-" indica un file
regolare. Una "d" indica una directory.
Il comando chmod è usato per cambiare i permessi di un file
o di una directory. Per usarlo, si devono specificare le impostazioni desiderate
dei permessi e il file (o i file) che si vuole modificare. Ci sono due modi per
specificare i permessi, ma in questa lezione ne illustrerò solo uno,
chiamato metodo con notazione ottale.
È comodo pensare all'impostazione dei permessi come a una serie di bit (che è proprio il modo in cui li intende il computer). Ecco come funziona:
rwx rwx rwx = 111 111 111
rw- rw- rw- = 110 110 110
rwx --- --- = 111 000 000
e così via...
rwx = 111 in codice binario = 7
rw- = 110 in codice binario = 6
r-x = 101 in codice binario = 5
r-- = 100 in codice binario = 4
Ecco che, se si rappresenta ciascuno dei tre insiemi di permessi (proprietario, gruppo e altri) come un singolo numero, si ha un modo alquanto conveniente per esprimere le possibili impostazioni dei permessi. Per esempio, se volessimo attribuire a un_file i permessi di lettura e scrittura per il proprietario, ma volessimo anche escluderne l'accesso agli altri, dovremmo dare:
[io@linuxbox io]$ chmod 600 un_file
Ecco una tabella di numeri che mostra tutte le impostazioni più comuni. Quelle che iniziano con "7" sono utilizzate con i programmi (in quanto abilitano l'esecuzione); le restanti sono per altri tipi di file.
| Valore | Significato |
| 777 |
(rwxrwxrwx) Nessuna restrizione dei permessi. Chiunque può fare qualsiasi cosa. Generalmente non è un'impostazione desiderabile. |
| 755 |
(rwxr-xr-x) Il proprietario del file può leggere, scrivere ed eseguire il file. Tutti gli altri possono leggerlo ed eseguirlo. Questa impostazione è comune per programmi che sono usati da tutti gli utenti. |
| 700 |
(rwx------) Il proprietario del file può leggere, scrivere ed eseguire il file. Nessun altro ha dei diritti. Questa impostazione è utile per programmi che solo il proprietario può usare e il cui accesso deve essere escluso agli altri. |
| 666 |
(rw-rw-rw-) Tutti gli utenti possono leggere e scrivere il file. |
| 644 |
(rw-r--r--) Il proprietario del file può leggere e scrivere il file, mentre tutti gli altri possono solo leggere il file. Un'impostazione comune per file di dati che tutti possono leggere, ma solo il proprietario può modificare. |
| 600 |
(rw-------) Il proprietario può leggere e scrivere il file. Tutti gli altri non hanno diritti. Un'impostazione comune per file di dati che il proprietario vuole tenere privati. |
Il comando chmod può essere usato anche per controllare i permessi di accesso alle directory. Ancora una volta, possiamo usare la notazione ottale per impostare i permessi, però il significato degli attributi r, w e x è diverso:
cd dir).Ecco alcune utili impostazioni per le directory:
| Valore | Significato |
| 777 |
(rwxrwxrwx) Nessuna restrizione sui permessi. Chiunque può elencare i file, creare nuovi file nella directory e cancellare file nella directory. Generalmente non è una buona impostazione. |
| 755 |
(rwxr-xr-x) Il proprietario della directory ha accesso completo. Tutti gli altri possono elencare i file della directory, ma non possono creare e cancellare i file. Questa impostazione è comune per le directory che si vogliono condividere con altri utenti. |
| 700 |
(rwx------) Il proprietario della directory ha accesso completo. Nessun altro ha dei diritti. Questa impostazione è utile per le directory che solo il proprietario può utilizzare e il cui accesso deve essere escluso agli altri. |
Spesso è necessario diventare super-utente per effettuare importanti
compiti di amministrazione del sistema ma, una volta terminati, non si dovrebbe
rimanere collegati in questo stato; di questo siete già stati avvertiti.
Nella maggior parte delle distribuziooni c'è un programma che può
dare un accesso temporaneo ai privilegi di super-utente. Questo programma si
chiama su (substitute user) e può essere usato in quei casi
dove serve diventare super-utente per eseguire pochi compiti. Per
diventare il super-utente, basta digitare il comando su.
Verrà richiesta la password del super-utente:
[io@linuxbox io]$ su
Password:
[root@linuxbox io]#
Dopo avere eseguito il comando su, avrete una nuova sessione di shell in qualità di super-utente. Per uscire dalla sessione di super-utente, digitare "exit" e ritornerete alla sessione precedente.
In alcune distribuzioni, Ubuntu in particolare, viene usato un metodo
alternativo. Al posto di usare su, adoperano il comando sudo.
Con sudo, a uno o più utenti vengono garantiti i privilegi di
superutente secondo le necessità. Per eseguire un comando come superutente, il
comando desiderato viene semplicemente preceduto dal comando sudo. Dopo che il
comando è stato dato, l'utente viene invitato a immettere la password
dell'utente anziché quella del superutente:
[io@linuxbox io]$ sudo
Password:
[root@linuxbox io]$
Potete cambiare il proprietario di un file usando il comando chown.
Ecco un esempio: supponiamo di voler cambiare il proprietario di un_file da
"io" a "tu". Potremmo fare così:
[io@linuxbox io]$ su
Password:
[root@linuxbox io]# chown tu un_file
[root@linuxbox io]# exit
[io@linuxbox io]$
Si noti che per cambiare il proprietario di un file si dev'essere
superutente. Per fare questo nel nostro esempio abbiamo impiegato il
comando su, poi abbiamo eseguito chown e, alla fine,
abbiamo digitato exit per ritornare alla sessione precedente.
chown funziona in questo stesso modo anche sulle directory.
Il gruppo proprietario di un file o directory può
essere cambiato con chgrp. Questo comando si usa nel modo seguente:
[io@linuxbox io]$ chgrp nuovo_gruppo un_file
Nell'esempio sopra, abbiamo cambiato il gruppo proprietario di
un_file dal suo precedente gruppo a "nuovo_gruppo".
Per utilizzare chgrp su di un file o una directory, bisogna esserne
il proprietario.
Nella precedente lezione ( Lezione 9 - Permessi), abbiamo visto alcune delle implicazioni di Linux come sistema operativo multi-utente. In questa lezione esamineremo la natura multitasking di Linux, e come è gestita con l'interfaccia a riga di comando.
Come con ogni sistema operativo multitasking, Linux esegue processi multipli simultanei. O, per meglio dire, questi processi sembrano davvero simultanei. In realtà, un computer con un singolo processore può eseguire un solo processo alla volta, ma il kernel Linux attribuisce a ogni processo una frazione del turno di esecuzione del processore, e ogni processo appare in esecuzione nello stesso momento.
Ci sono diversi comandi che possono essere usati per controllare i processi. Questi sono:
L'argomento che tratteremo ora potrà sembrare piuttosto oscuro, ma
risulterà molto pratico per l'utente medio che lavora per lo più
con l'interfaccia grafica. È possibile che non lo sappiate, ma la
maggior parte (se non tutti) dei programmi grafici possono essere eseguiti
dalla riga di comando. Ecco un esempio: c'è un piccolo programma di
nome xload, fornito col sistema X Window, che mostra un grafico
rappresentante il carico del sistema. Puoi eseguire questo programma digitando:
[io@linuxbox io]$ xload
Notate l'apparire della piccola finestra di xload, che inizia a mostrare il grafico del carico del sistema. Notate anche che, dopo che avete lanciato il programma, il prompt non è ricomparso. La shell sta aspettando che il programma finisca prima di ridare il prompt. Se chiudete la finestra di xload, il programma xload termina e ritorna il prompt.
Ora, per renderci la vita un po' più facile, eseguiremo ancora il
programma xload, ma questa volta lo metteremo in background così
il prompt ritornerà visibile. Per fare questo, eseguiamo xload
nel modo seguente:
[io@linuxbox io]$ xload &
[1] 1223
[io@linuxbox io]$
In questo caso, il prompt è ritornato perché il processo è stato messo in background.
Ora, immaginate di aver dimenticato di usare il simbolo "&" per mettere
il programma in background. C'è ancora un po' di speranza. Potete
digitare control-z e il processo sarà sospeso. Il processo esiste
ancora, ma è inattivo. Per riattivare il processo in background, digita
il comando bg (abbreviazione di background). Ecco un esempio:
[io@linuxbox io]$ xload
[2]+ Stopped xload
[io@linuxbox io]$ bg
[2]+ xload &
Ora che abbiamo un processo in background, potrebbe essere utile visualizzare
una lista dei processi avviati da noi. Per fare questo, possiamo usare sia il
comando jobs, sia ps, un comando ancora più potente.
[io@linuxbox io]$ jobs
[1]+ Running xload &
[io@linuxbox io]$ ps
PID TTY TIME CMD
1211 pts/4 00:00:00 bash
1246 pts/4 00:00:00 xload
1247 pts/4 00:00:00 ps
Supponendo che si abbia un programma che non risponde più;
come fate a sbarazzartene?
Userete il comando kill, naturalmente. Proviamolo su xload. Prima
dovete identificare il processo che volete uccidere. Per far questo potete
usare jobs o ps. Se usate jobs otterrete un numero
di job. Con ps vi viene fornito un id del processo (PID). Lo faremo
in entrambi i modi:
[io@linuxbox io]$ xload &
[1] 1292
[io@linuxbox io]$ jobs
[1]+ In esecuzione xload &
[io@linuxbox io]$ kill %1
[io@linuxbox io]$ xload &
[2] 1293
[1] Terminato xload
[io@linuxbox io]$ ps
PID TTY TIME CMD
1280 pts/5 00:00:00 bash
1293 pts/5 00:00:00 xload
1294 pts/5 00:00:00 ps
[io@linuxbox io]$ kill 1293
[2]+ Terminated xload
Anche se il comando kill è usato per "uccidere" i processi, il suo scopo
reale è quello di inviare segnali ai processi. Quasi sempre si
finisce con l'inviare un segnale che dice al processo di sparire, ma di segnali
se ne possono inviare anche di altro tipo. I programmi (se scritti
adeguatamente) rimangono in ascolto dei segnali che provengono dal sistema
operativo e rispondono a questi, molto spesso per consentire dei metodi di
terminazione non aggressivi. Per esempio, un editor di testo può
ascoltare ogni segnale che indica che l'utente è uscito dal sistema, o
che il computer sta per essere spento. Quando l'editor riceve questo segnale,
salva il lavoro in corso prima di uscire. Il comando kill può
inviare una varietà di segnali ai processi. Digitando:
kill -l
si avrà una lista dei segnali che sono inviabili con kill.
La maggior parte sono piuttosto oscuri, ma alcuni sono utili da conoscere:
| Segnale | Nome | Descrizione |
| 1 | SIGHUP |
Segnale di aggancio (Hang up). I programmi possono ascoltare questo segnale e agire (o non agire) di conseguenza. |
| 2 | SIGINT |
Segnale di interruzione. Questo segnale è inviato ai processi per interromperli. I programmi possono elaborare questo segnale e agire di conseguenza. Puoi dare questo segnale anche direttamente digitando control-c nella finestra del terminale dove il programma viene eseguito. |
| 15 | SIGTERM |
Segnale di conclusione. Questo segnale è inviato ai processi per concluderli. Inoltre, i programmi possono elaborare questo segnale e agire di conseguenza. Puoi inviare questo segnale anche direttamente digitando control-c nella finestra di terminale dove il programma è stato eseguito. Questo è il segnale predefinito inviato dal comando kill se non è specificato nessun segnale. |
| 9 | SIGKILL |
Segnale di kill. Questo segnale provoca la conclusione immediata del processo dal kernel Linux. I programmi non possono captare questo segnale. |
Ora, supponiamo che abbiate un programma bloccato senza speranza e vogliate liberavene. Ecco cosa dovete fare:
ps per ottenere l'id del processo (PID) che
volete terminare.kill per questo PID.
[io@linuxbox io]$ ps x | grep programma_difettoso
PID TTY STAT TIME COMMAND
2931 pts/5 SN 0:00 programma_difettoso
[io@linuxbox io]$ kill -SIGTERM 2931
[io@linuxbox io]$ kill -SIGKILL 2931
Nell'esempio sopra abbiamo usato il comando ps con l'opzione x per
elencare tutti i nostri processi (anche quelli non avviati dal nostro terminale).
Inoltre, abbiamo ridiretto tramite una pipe l'output del comando
ps verso grep per avere l'elenco soltanto dei programmi che
ci interessano. Poi abbiamo usato kill per inviare un segnale
SIGTERM al programma difettoso.
Nella pratica, è molto comune farlo nel modo descritto di seguito
poiché il segnale predefinito inviato da kill è SIGTERM e kill
può usare anche il numero del segnale al posto del nome:
[io@linuxbox io]$ kill 2931
Poi, se il processo non si conclude, forzatelo con il segnale SIGKILL:
[io@linuxbox io]$ kill -9 2931
Qui si conclude la serie di lezioni di "Learning the Shell". Nella prossima serie, "Writing shell scripts," vedremo come automatizzare l'esecuzione di compiti con la shell.