
|
|
<- SL: Intro - Indice Generale - Copertina - SL: Router -> |
|
Sistemi Liberi
L'articolo...Nel numero scorso abbiamo fatto una panoramica sulle basi della sicurezza, affrontando temi quali firewall, application proxy, stateful inspection, ecc. Abbiamo anche visto un esempio di cosa significhi, in termini pratici, applicare quest'ultima al nostro packet filter preferito, Netfilter. Sono stati tirati in ballo anche i cosiddetti "application proxy", senza però vedere oggettivamente qualche esempio pratico... In questo numero, quindi, daremo uno sguardo da vicino ad un proxy web: ebbene sì, è proprio lui, Squid! Vedremo come il più famoso caching proxy possa essere utilizzato come firewall applicativo (e senza patch strane, semplicemente tramite alcuni parametri quasi sempre ignorati)... Ma non finisce qui! Per fare arrabbiare i puristi, lo vedremo all'opera in un caso reale, utilizzandolo per proteggere Microsoft IIS! E da oggi, guai a chi dice che siamo di parte... ;) |
Molti staranno pensando che mi sono giocato il cervello: parlare di software proprietario
all'interno del Pluto?!? E non pago, addirittura del "famigerato" MS IIS??!? Certo! Pur credendo fermamente
nella bellezza di Linux (e del software libero), non credo che i tempi siano ancora maturi per farlo entrare
nel mondo "del business" sfondando la porta! Non mi sto ovviamente riferendo a carenze tecniche, ma penso che
la mentalità comune non sia ancora pronta...
Discorsi filosofici a parte, vorrei fare notare che molto spesso la scelta della piattaforma tecnologica per un web server
non è poi così libera: chi fa il mio stesso lavoro si sarà certamente imbattuto in piccoli siti web che
storicamente si appoggiano ad un db MS Access, oppure portali interamente scritti in ASP (il cui porting in PHP costerebbe
uno sproposito)... Il mondo reale è differente da quello teorizzabile sulla base delle nostre bellissime ideologie! Linux necessita
ancora di un po' di pubblicità per poter finalmente uscire dal ruolo di sistema operativo per smanettoni; e quale
migliore occasione, se non quella di poter fare da "angelo custode" a MS IIS...
Vediamo innanzi tutto di capire cosa può accadere ad un server web se lo lasciamo
senza protezione: per rendere tutto molto chiaro e comprensibile, ho scelto di usare una famosa vulnerabilità, la
cosiddetta "Extended Unicode Directory Traversal Vulnerability" (per i dettagli, vedi l'appendice A
e i riferimenti). Ho
scelto questo bug per svariati motivi: il primo è che Nimda si basava proprio su di esso. E il secondo è che, a
giudicare dai log dei miei IDS, sembra che ci siano ancora tanti web server non patchati per questo tipo di bug... Male! Non
ultimo, infine, il fatto che il numero delle piattaforme colpite da questo bug è notevole: MS IIS, versioni 4 e 5, MS Personal
Web Server, varie versioni di Cisco Call Manager, ecc...
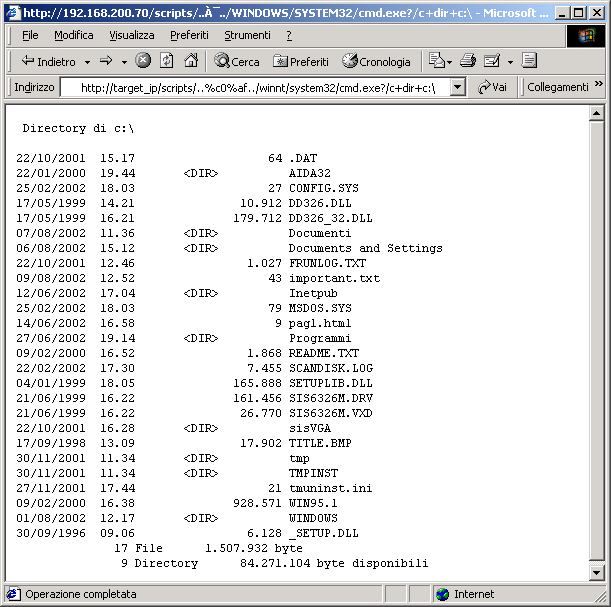
Prendiamo allora una installazione "fresca" di Internet Information Server: il nostro scopo è
quello di arrivare ad eseguire il programma "cmd.exe", cioè l'interprete dei comandi. Sono solamente due le cose che
ci separano dal nostro intento: sapere dove è posizionato il file (in quale directory) rispetto alla root del sito, e fare in modo
che il web server lo esegua. Entrambe queste cose sono presto fatte: il 99.5% delle installazioni dei programmi utilizza le directory
di default, e IIS crea automaticamente una directory /scripts/ assegnandovi i permessi di esecuzione. Perfetto, basta lanciare
cmd.exe proprio da /scripts/. E qui entra in ballo il bug: se utilizzassimo i caratteri standard "../.." per accedere alla directory
superiore, il web server ci bloccherebbe perché programmato per filtrare i cosiddetti "parent path". Se io però uso
la rappresentazione UNICODE per la "/" (ad esempio "%c0%af", ma non è l'unica), il gioco è fatto. Facendola breve (non
siamo qui a fare corsi per script kiddies), in questo modo riesco ad eseguire l'interprete dei comandi, e posso perfino passargli
eventuali parametri. Ecco come eseguire qualche operazione sul server remoto:
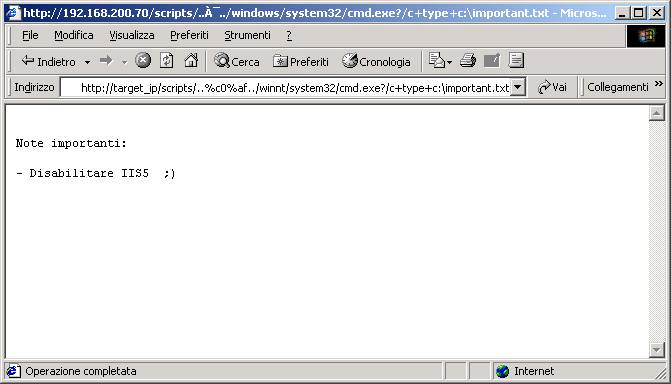
http://target_ip/scripts/..%c0%af../winnt/system32/cmd.exe?/c+dir+c:\ http://target_ip/scripts/..%c0%af../winnt/system32/cmd.exe?/c+type+c:\important.txt http://target_ip/scripts/..%c0%af../winnt/system32/cmd.exe?/c+copy+..\..\winnt\system32\cmd.exe+cmd1.exe |
Utilizzando questi comandi inserendoli nel nostro browser preferito e sostituendo l'IP del server IIS, vedremo i risultati: il
primo esegue un semplice "dir c:\", il secondo visualizza il contenuto del file "c:\important.txt", mentre l'ultimo copia il "cmd.exe"
nella directory /scripts/ (azione indispensabile
per eseguire altre operazioni, ma che esulano dagli scopi di questo articolo). Se non avete un server IIS di test a portata di mano,
potete trovare linkati gli output del primo e del secondo esempio
visti sopra...
Che cosa possiamo vedere da questi esempi? Semplice, che la chiave di volta è proprio
l'interprete dei comandi "cmd.exe": basta bloccarne l'accesso, e tutti i tentativi di exploit diventano inefficaci. Inutile dire
che utilizzare un application proxy per bloccare questo tipo di attacco non è proprio indispensabile: ad onor del vero, per
bloccare Nimda sarebbe bastato applicare la hotfix uscita mesi prima, oppure impostare le corrette permission di file system
(che impediscono a IIS l'esecuzione dei file di sistema), ecc. Ma per i nostri scopi, prettamente accademici, utilizzare un proxy
web è estremamente efficace.
Squid (www.squid-cache.org) è per molti una vecchia conoscenza: ormai sono noti i vantaggi del suo utilizzo come cache proxy per accelerare la navigazione, centralizzarne il controllo, permettere l'utilizzo di liste di accesso, gestire la banda, ecc... Non ho intenzione di affrontare in questa sede l'utilizzo di Squid come proxy cache, bensì di passare in rassegna i parametri che ne permettono l'utilizzo come application proxy, al fine di "proteggere" uno (o più) web server posto dietro di esso.
|
|
|
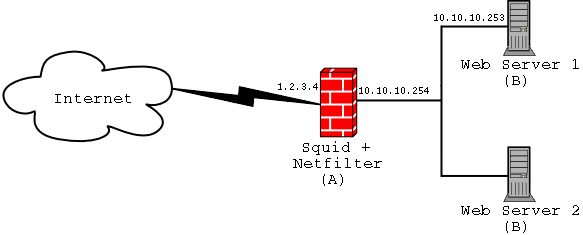
Sono possibili varie configurazioni di rete: l'application proxy può essere installato sulla stessa macchina che monta il web server, oppure su di un server separato. Personalmente, in Fig.1 ho riportato quest'ultima soluzione per vari motivi: primo, è buona norma separare il firewall o il proxy dai server applicativi (per ovvi motivi di sicurezza). Inoltre, come nella figura, un unico server Squid può proteggere più web server: si utilizza così un solo application proxy per proteggere una intera web farm! In ultimo (ma esula dagli scopi dell'articolo), Squid può essere utilizzato come load balanced per distribuire il carico su più server web, come già permesso da questa configurazione.
Da questo momento in poi, quindi, partiremo dal presupposto di avere una macchina A su cui installeremo Squid, ed un web server in esecuzione sulla macchina B. In genere, per aumentare la sicurezza del sistema si usa configurare il web server per essere in ascolto su di una porta non standard, ad esempio la 81 (vedi l'Appendice B, che illustra come cambiare le porte): questo piccolo accorgimento fa sì che il traffico web possa arrivare al server solamente passando attraverso il proxy; nel caso i due servizi siano su due macchine distinte, questo trucchetto ha poca importanza, ma può risultare molto comodo nel caso in cui fossimo costretti ad installare il tutto sullo stesso server.
Venendo alle cose serie, una volta installato Squid (dai sorgenti o dai binari pacchettizzati, secondo le preferenze personali), andremo ad editare il file di configurazione: in questa sede non scenderemo nei dettagli su come configurare Linux come router, e non considereremo neppure il tuning di Squid, o comunque la sua configurazione di base. Indicheremo quindi esclusivamente i parametri da modificare (realmente pochi) per fare funzionare il nostro Squid come un application proxy. Vorrei anche sottolineare che è possibile abbinare le funzionalità di firewalling a quelle (già note) di caching: in questo modo, le pagine richieste dai client vengono salvate anche in cache, col risultato di alleggerire anche il web server nel caso vi siano pagine visitate frequentemente. Di seguito elenco i parametri minimi:
http_port 80 #Configuro Squid in modo che ascolti sulla porta 80 icp_port 0 #Disabilito le query ICP da e verso altri proxy. emulate_httpd_log on #I log creati potranno poi essere utilizzati per statistiche di accesso http_access allow all #Consento le connessioni dall'esterno httpd_accel_host <ip_di_B> #L'indirizzo del vero web server httpd_accel_port 81 #La porta su cui ascolta il vero web server httpd_accel_single_host on #Ottimizzo per proteggere un solo server web httpd_accel_with_proxy on #Da settare se si vogliono anche le funzioni di caching httpd_accel_uses_host_header on #In caso in cui il server web utilizzi i VirtualHost |
Vediamo di commentare brevemente i parametri sopra utilizzati: http_port è abbastanza
noto, e ci consente di selezionare su quale porta sarà in ascolto Squid. Ovviamente selezioniamo la 80, per fare in modo
che il nostro proxy si comporti come un web server.
Il parametro icp_port viene utilizzato nel caso in cui Squid debba comunicare
con altri proxy per scambiarsi informazioni sulla cache (è il caso delle gerarchie di server proxy): visto che il nostro deve essere un application proxy, ci preoccuperemo di disabilitare
tale feature.
Quasi certamente, se abbiamo un web server avremo anche un sistema per generare le statistiche di accesso al sito (ad esempio
utilizzando il caro buon Webalizer). Ma nel caso si utilizzi un application proxy, tutti gli accessi al web server risultano effettuati
dalla macchina su cui è in esecuzione Squid, e quindi i nostri log file risultano spesso poco utili. Per questo motivo,
conviene analizzare gli stessi log di Squid, i quali contengono tutte le informazioni necessarie all'analisi statistica; l'unico problema
è che il formato dei log di un proxy è diverso da quello standard di un server web. Per questo, è comodo
utilizzare il parametro emulate_httpd_log, in modo tale da far generare a Squid i log di accesso in un formato utilizzabile
appunto da un programma di statistiche.
Dopo aver permesso l'accesso a tutti i client, tramite la direttiva http_access allow all, iniziamo a vedere i parametri
realmente interessanti al nostro scopo: per prima cosa, definiamo l'IP del vero server web (la macchina B come da Fig.1) e la
relativa porta non standard tramite i parametri httpd_accel_host e httpd_accel_port. Questi sono i soli parametri
fondamentali al nostro scopo. Gli ultimi tre riportati nel precedente riquadro non sono obbligatori, ma possono tornarci utili in
particolari occasioni. Vediamone l'utilizzo: httpd_accel_single_host permette di specificare se dietro al proxy vi sia una
sola macchina o più di una. Questo, come abbiamo accennato all'inizio, può essere molto comodo nel caso in
cui si voglia utilizzare un solo proxy per una intera web farm. I dettagli di questo tipo di configurazione sono oltre lo scopo del
nostro articolo, e sono facilmente intuibili leggendo direttamente il file di configurazione di Squid. Molto più importanti sono,
invece, httpd_accel_with_proxy e httpd_accel_uses_host_header: il primo ci permette di svolgere le funzioni di
application proxy, affiancando il caching delle pagine richieste (cosa che permette di alleggerire il carico di lavoro del web
server). Il secondo parametro invece è indispensabile nel caso in cui la macchina B utilizzi i cosiddetti "host header" per
sfruttare i VirtualHost.
L'ultima cosa che ci resta da fare è assicurarci che un client non possa in alcun modo
raggiungere il server web senza passare dal proxy. Per fare ciò disabilitiamo l'IP forwarding e, da veri paranoici, utilizziamo
anche Netfilter. Il seguente script fa al caso nostro:
#!/bin/bash echo Disable ip forwarding... echo 0 > /proc/sys/net/ipv4/ip_forward echo Enter Paranoid mode... iptables -P FORWARD DROP echo Done |
Perfetto! Abbiamo i parametri fondamentali per verificare il funzionamento del nostro proxy; ora non ci resta che vederlo in azione. Avviamo Squid e connettiamoci al server web: facendo riferimento ai dati di Fig. 1, ora l'indirizzo sarà http://1.2.3.4. Se tutto è andato bene, dovremmo osservare che sui log di Squid apparirà una connessione proveniente dal nostro client, mentre sul server web risulterà un accesso dal nostro application proxy. Bingo! I conti tornano. E' chiaro che fino ad ora non abbiamo impostato nessuna restrizione nei confronti del nostro "cmd.exe" (provare per credere: se riproviamo il nostro piccolo "exploit", rispetto a prima non è cambiato nulla). Procediamo quindi con la parte più utile del nostro gioco, le ACL. Tutto si basa su queste due semplici righe:
acl iis_bug urlpath_regex -i cmd.exe http_access deny iis_bug |
Direi che il significato è abbastanza chiaro: la prima definisce una ACL che si basa sul riconoscimento della stringa "cmd.exe" all'interno dell'indirizzo richiesto. La seconda riga nega l'accesso a tale ACL. L'unico accorgimento basilare è che la seconda direttiva va posizionata prima di quella vista precedentemente (http_access allow all). Se ora ritentiamo il nostro exploit, dovremmo vedere comparire, questa volta, la ben nota pagina di errore di Squid, in cui è riportato che il controllo di accesso non permette di visualizzare la pagina.
L'esempio qui portato mostra come sia oggettivamente facile configurare un application
proxy per proteggere i nostri server web. Non solo: abbiamo visto che basta una semplicissima ACL per
bloccare praticamente ogni tipo di attacco a Microsoft IIS volto ad eseguire comandi sul web server. Con questo non sto
ovviamente dicendo che possiamo anche non applicare le patch! Semplicemente, molto spesso un buon application proxy
è in grado di bloccare attacchi che sfruttano bug per cui non sono ancora disponibili aggiornamenti. Inoltre, vorrei
far riflettere sul fatto che sarebbe bastato settare correttamente le permission sul file system, e questo tipo di worm non
avrebbe potuto fare alcun danno. Evitiamo ulteriori commenti...
Tornando al mondo Linux e ai nostri firewall, vorrei fare un'altra piccola considerazione: chi di voi
ha installato Netfilter dai sorgenti, avrà notato un modulo "ipt_string", che permette di decidere la sorte di un pacchetto
in base all'eventuale presenza di una stringa di testo in esso contenuta. E allora, perché complicarci la vita
installando un proxy, visto che in prima analisi potrei pensare di fare la stessa cosa con un packet filter? Per tanti motivi:
primo, un application proxy non si limita a bloccare questo tipo di attacchi, ma lavorando
a livello applicazione (7) del modello ISO/OSI è in grado di filtrare tutte le richieste non conformi al protocollo (e
questo è un vantaggio enorme). Il secondo motivo fondamentale sta nel tipo di filtraggio operato: come già
detto (vedi l'articolo precedente "Teoria del firewall",
http://www.pluto.linux.it/journal/pj0207/teoria_fw.html), Netfilter è un packet filter, e quindi opera a livello 3 (o 4) del
modello ISO/OSI. Di conseguenza, un eventuale filtraggio avviene "droppando" i pacchetti contenenti la stringa. Se ripensate
a come avviene l'handshaking e la comunicazione su TCP/IP, questo significa che la connessione non viene chiusa. In
pratica, nel momento in cui un attacker si connette al nostro web server, egli apre una sessione su di esso; invia quindi la richiesta
http, contenente la stringa incriminata. Il nostro firewall, posto a monte o sulla stessa macchina del server web, riconosce che la
stringa è pericolosa, e "droppa" il pacchetto prima che esso arrivi al server. Risultato: il server è effettivamente salvo,
ma la connessione con l'attacker è rimasta half-open, e rimarrà in tale stato fino al timeout impostato sul server stesso.
Questo significa bloccare un socket per un certo periodo di tempo. Se l'attacker è abbastanza sveglio, può farci un
DoS al server in maniera molto semplice: gli basterà fare un loop ripetendo il tentativo di richiesta della stringa bloccata, e
in brevissimo tempo la mia macchina non sarà più in grado di accettare nessuna connessione (a causa di tutti i socket
occupati). Nel caso dell'application proxy le differenze sono enormi: in primis, solo il proxy stesso si connette realmente al server web.
Inoltre, nel caso venga riconosciuta la stringa, la connessione non viene effettivamente chiusa, ma semplicemente viene restituita
una pagina web di errore: in questo modo, tutto è salvo.
Va fatta anche una importante considerazione riguardo al cosiddetto "information leakage": questo
sistema ci permette di
mantenere un buon livello di sicurezza per il nostro web server. Va però notato che un attacker che tenta l'exploit a mano si
ritrova di fronte la schermata tipica di Squid: in questo momento, gli stiamo regalando informazioni preziose. Inoltre, nella pagina
standard è presente in bella vista l'IP e la porta del web server reale! Si, decisamente troppe informazioni. E' quindi furbo
utilizzare un ulteriore parametro di Squid, deny_info la cui sintassi è:
deny_info CUSTOM_HTML_PAGE nome_della_acl
Possiamo quindi crearci una bella paginetta, che utilizza i css del nostro sito, in cui riportiamo un errore generico. Protetti e
mascherati!
Un'ultima riflessione: la ACL da noi utilizzata si basa su di una espressione regolare molto semplice.
Ovviamente, tale ACL non ha alcun effetto se la stringa "cmd.exe" viene spezzata tramite, ad esempio, l'utilizzo di codici UNICODE
nulli (che in pratica non producono un equivalente ASCII). Ciò non significa che non si possa scrivere un redirector che
tenga conto anche di questo! Quante cose da fare, quante da sapere... e quanto poco tempo!
Extended Unicode Directory Traversal Vulnerability
Detta in parole molto povere, l'Unicode è una sorta di codifica (simile a quella ASCII) utilizzata per ovviare
al fatto che esistono differenti alfabeti. I web server, primo fra tutti IIS, interpretano i codici Unicode, e li trasformano
nell'equivalente simbolo del character set di appartenenza.
La cosiddetta "traversal vulnerability" è la possibilità di "uscire" dalla root directory di un determinato servizio,
nel nostro caso il server web. Questo tipo di bug è, già di per sè, abbastanza pericoloso; a questo, si
aggiunge il fatto che in eventuale attacker (o un worm, come nel caso di Nimda) sa quasi sempre dove mettere le mani una volta
scovata la falla (visto che una notevole quantità di servizi viene solitamente installata utilizzando i parametri di default).
Normalmente, IIS "blocca" le richieste di pagine (o file) esterni alla document root; questo tipo di controllo,
però, viene eluso utilizzando i codici UNICODE al posto del carattere "\".
Come abbiamo detto poc'anzi, è vivamente consigliato mantenere il server
web in ascolto su di una porta differente dalla "classica" 80. Ovviamente, se poi si decide di installare web e proxy
sulla stessa macchina, la scelta è quasi forzata (quasi, visto che si potrebbe comunque mantenere Squid in ascolto
sulla porta 8080, e utilizzare iptables per redirigere su di esso tutto il traffico verso la porta 80, proveniente dalla interfaccia
esterna. Ma oltre ad essere una soluzione macchinosa, è meno sicura). Sempre nel caso si installi tutto sullo stesso
server, è consigliabile abilitare il servizio http solo sull'interfaccia di loopback.
Se il server web è Microsoft IIS, si può impostare la porta da utilizzare tramite la
finestra "Proprietà". Nel caso invece che il server web sia Apache, il parametro per settare la porta in ascolto
sulla 81 è:
Listen 81 #Listen 127.0.0.1:81 in caso sia tutto sulla stessa macchina |
- "Microsoft IIS and PWS Extended Unicode Directory Traversal Vulnerability":
http://online.securityfocus.com/bid/1806
- "SQUID - A User's Guide":
http://squid-docs.sourceforge.net/latest/html/
- "UNICODE Home Page": http://www.unicode.org/
Microsoft, Internet Information Server e Internet Explorer sono marchi registrati.
Tutti i nomi dei prodotti citati sono riconosciuti come marchi delle rispettive case produttrici.
L'autoreTommaso Di Donato è sistemista Linux (Red Hat Certified Engineer) e Microsoft dal 1998; è stato dba Oracle presso la PA, nell'ambito del progetto di informatizzazione dei Centri Protesi INAIL in Italia. Ha lavorato presso un portale Internet, in qualità di sistemista e dba; si occupa inoltre di sicurezza informatica e TLC. |
|
|
<- SL: Intro - Indice Generale - Copertina - SL: Router -> |
|
{kind=link}
{kind=link}