6. La toolchain di DocBook
Il modo pi¨ semplice per impaginare documenti XML-DocBook × utilizzare gli strumenti di xmlto. Questi strumenti sono forniti con Red Hat; gli utenti di Debian possono ottenerli con il comando apt-get install xmlto.
Normalmente, quello che dovreste fare per creare un documento XHTML da un sorgente DocBook × qualcosa di simile:
bash$ xmlto xhtml foo.xml bash$ ls *.html ar01s02.html ar01s03.html ar01s04.html index.html |
In questo esempio abbiamo trasformato un documento XML-DocBook chiamato foo.xml, composto da tre sezioni principali, in una pagina di indice e altre due parti. Ma mettere tutto in una sola pagina × altrettanto facile:
bash$ xmlto xhtml-nochunks foo.xml bash$ ls *.html foo.html |
Infine, ecco come fare per creare un documento Postscript:
bash$ xmlto ps foo.xml # To make Postscript bash$ ls *.ps foo.ps |
Alcune vecchie versioni di xmlto potrebbero essere pi¨ verbose, riportando messaggi quali "Coverting to XHTML" e così via.
Per trasformare i vostri documenti in HTML o Postscript avrete bisogno di uno strumento che possa applicare al vostro documento le direttive di DocBook DTD e del foglio di stile adatto. Ora mostreremo come combinare gli strumenti open-source per compiere questo lavoro:
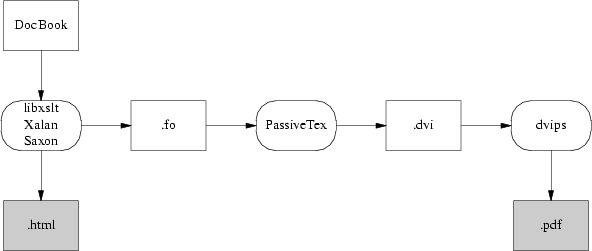
Attuale catena XML-DocBook
L'analisi del documento e l'applicazione del foglio di stile possono essere realizzati tramite uno di questi tre programmi: xsltproc, il parser distribuito con la RedHat 7.3 e versioni successive, oppure Saxon o Xalan, due programmi scritti in Java.
Generare un documento XHTML di alta qualitÓ con DocBook × abbastanza semplice; il fatto poi che XHTML sia semplicemente un altro tipo di XML DTD × di grande aiuto. La traduzione in HTML si ottiene applicando un semplice stylesheet, e fine della storia. Generare un RTF in questo modo × altrettanto semplice e da un XHTML o RTF × facile generare un testo ASCII in un attimo.
Caso delicato × la stampa. ╚ difficile generare un documento di alta qualitÓ per la stampa (che in pratica significa un documento tipo Adobe o Portable Document Format, una forma compressa di PostScript). Farlo bene comporta dover automatizzare il giudizio attento di un tipografo nel passaggio dal livello di contenuto a quello di presentazione.
Prima di tutto, uno stylesheet trasforma e traduce un documento strutturato DocBook DTD in un altro documento scritto in un dialetto di XML, chiamato FO (Formatting Objects). Il markup di FO × molto pi¨ vicino ad una struttura tipo presentation-level; potete pensarla come ad una sorta di XML funzionalmente equivalente a Troff (NdT. la struttura delle pagine man per intenderci). Subito dopo deve essere trasformato in Postscript per poi essere inpacchettato in un PDF.
Nella toolchain distribuita con RedHat, questo lavoro × fatto da una macro di TeX chiamata PassiveTeX. Questa traduce il documento in FO prodotto da xsltproc nel linguaggio TeX di Donald Knuth. TeX × stato uno dei primi progetti open-source, un vecchio ma potentissimi linguaggio di formattazione presentation-level molto amato dai matematici (ai quali fornisce una serie di strumenti particolarmente adatti per scrivere documenti contenenti formule matematiche). TeX × anche molto utile per compiti di composizione di base, quali il kerning, il riempimento di linee e la gestione delle ifenazioni. Il formato di output del TeX, chiamato DVI (DeVice Independent), viene poi trasformato in un PDF.
Se pensate che questa lunga e tortuosa catena che va da XML alle macro TeX, per poi passare al DVI ed infine al PDF sia delicatissimo, beh, avete perfettamente ragione: sferraglia, ansima ed ha delle orribili verruche. I font sono un grosso problema, dal momento che XML, TeX e PDF fanno uso di modelli molto diversi per la gestione dei font. Inoltre, la gestione della localizzazione e dell'internazionalizzazione × un vero incubo. Forse, l'unico punto a favore di questo percorso × che funziona.
Una soluzione pi¨ elegante sarebbe FOP, un traduttore che passa direttamente da FO a Postscript, sviluppato con il progetto Apache. Con FOP il problema dell'internazionalizzazione ×, se non completamente risolto, almeno ben delimitato; gli strumenti XML utilizzano tutti l'Unicode attraverso FOP. La mappatura del singolo carattere nel font × anche un problema importante di FOP. L'unico problema in questo approccio × che non funziona, almeno per il momento. Ad Agosto 2002, il progetto FOP × ad uno stato alpha, quindi utilizzabile, ma ancora non rifinito e con diverse caratteristiche mancanti.
Ecco quello che fa la toolchain FOP:
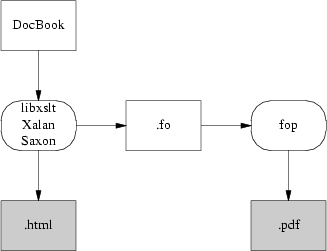
Futura catena XML-DocBook con FOP.
FOP ha giÓ della concorrenza. C'× un altro progetto, chiamato xsl-fo-proc, che aspira agli stessi obiettivi di FOP, ma × scritto in C++ (× quindi pi¨ veloce di Java ed × indipendente dall'ambiente Java). Nell'Agosto 2002, il progetto xsl-fo-proc era allo stato alpha, non molto distante da FOP.